釣果情報を分析しようとしたらその手前で詰まった話
この記事は、「Unagi-Network Advent Calendar 2023」18日目の記事になる予定でしたが、1週間遅刻した上にやりたいことすらできませんでした…
Unagi-Network Advent Calendar 2023 - Adventar
今回は反省も込めて、何をしたかったか、現状どうなのかを書こうと思います。
はじめに
皆さん、釣りは行かれますか?最近色々あって行けていないのですが、私は数年前まで月1ペースくらいで雨の降っていない日に釣りに行ってました。最近はほとんど行けていないのですが、2023年9月に行った釣り場では、毎日気温・水温・天気・風速等の情報や、釣果情報をWebページに掲載していることに気づきました*1。
今回のように様々な釣りに関わる情報を毎日上げているのを見ると「Webページからデータを集めて分析すれば、その釣り場で釣りたい魚種に合わせて最適な日が分かるのでは…?」みたいなことを考えました。それで、Webページから情報をすべて持ってきて、それを基に分析しようとしたのが今回の話です。
注意点
スクレイピング初心者の記事です。プロからしたらあるあるみたいな話の山だと思います。また、詰まった点でWebページに対してネガティブと受け取られる内容を書いているかもしれませんが、釣果情報を上げてくれている時点で神なので、それをうまくデータとしてまとめられていない自分が100%悪いです。
要約
Webページからデータを抽出しようとスクレイピングを試したら、色々と詰まったので、その時の知見をまとめました。
詰まった点
思わぬところにある環境依存文字
釣果情報を眺めていると、時々「20㎝の○○が釣れていました」という記載があるのですが、よくよく見ると「㎝」が環境依存文字になっていて、その関係でファイル保存時にエラーが発生しました。SJISやEUC等、色々試したのですが、結局JIS X 0213にしないと保存できないことが判明しました*2。
import requests response = requests.post(URL) response.encoding = 'euc_jisx0213' #JIS X 0213でエンコーディングする場合はこっち #response.text.encode().replace(b'\xad\xd1', b'cm') #環境依存文字"㎝"をcmに修正する場合はこっち
普段何気なく使うかもしれない環境依存文字は、想像以上に厄介な存在ということが分かりました…
データがフリーコメントに近い
気温・水温・天気・風速等の情報や、釣果情報を集めようとする際、特に気温・水温・天気・風速等の情報がフリーコメントに近い形式で記載されていました。 特に悩ましいのが下記のようなデータの書き方で、こういったケースもすべて対応するようにプログラムを書いていたら日が昇っていました。
■通常 キー1:データ1 キー2:データ2 ■とある日 キー1:データ2データ1
また、魚種によって単位が異なっていて、ある魚はcm表記であるのに対して、ある魚はkg表記であるケースもあるので、単位に応じてデータの抽出を工夫する必要がある等の問題もありました。
釣果情報の釣った魚の数が場所によって変わっている
とある日の釣果情報を確認すると、表形式で書いてある釣った魚の数と、フリーコメント欄に書いてある釣った魚の数が異なっていました。これを確認していって分かったこととして、表の方には4桁までの釣果情報しか記載されておらず、5桁以上魚が釣れた日はフリーコメント欄に記載されていることが分かりました。
そのため、表とフリーコメント欄の両方を確認することで、より正確な情報を取得する必要がありました。
まとめ
今回データをまとめて分析できるようにするための前段階をやりましたが、データセットが存在しない状況下でのデータ収集が想像の数十倍も面倒であることがよくわかりました。スクレイピングを行うにしても、かなり記載方法が整理された場所からデータを引っ張ってくるイメージが強かったですが、実際には上記のような様々な罠が潜んでいて、これを分析可能なデータとして整理するのはかなり大変です。こういったことを身に染みて理解できたのは一つの知見だったのかな、と思います。
それはそれとして、もともとやりたかった分析は全くできていないので、来月以降に実施して、次こそはそれに関する記事を上げます…
余談
スクレイピングを行う際、1リクエストにつき2秒スリープする仕様にしていた影響でかなり待ち時間ができたので、寿司打で遊んでいました。 久々にやりましたが、一発勝負が全然できなくなっていたので、普通でのんびり遊びました。こちらは完全に力が衰えていたので、勘を取り戻します…
AWSでインスタンスに合わせてルートテーブルを自動変更したかった話
この記事は、「Unagi-Network Advent Calendar 2023」17日目の記事になります。
Unagi-Network Advent Calendar 2023 - Adventar
3年ほど記事を更新していませんでしたが、Advent Calenderにお誘いいただいたので、久々に更新しようと思います。
注意点
AWS初心者なので、そもそもの前提を含めて、もっと良い解決方法があるかもしれません。
要約
LambdaとEventBridgeを使い、検証用インスタンスが立ち上がる度にルートテーブルを自動で変更する仕組みを作成しました。また、今後同じ人がもし万が一存在していた場合のため、それまでの過程や失敗談をまとめました。
背景
とある日、検証のために1つのAWS VPC上で「インスタンスA←→検証用インスタンス←→インスタンスB」の通信を行う必要性が出たため、下記のVPC環境を用意しました。

この時、VPCのルートテーブルは、デフォルトでは「同一VPC内のインスタンス間の通信は、インスタンス間で直接通信が行われる」仕様になっているため、「インスタンスA←→インスタンスB」の通信になってしまいます。そこで、VPCのルートテーブルにおいて、「Public Subnet 2/3において、Public Subnet 1/2/3の通信は全て検証用インスタンスのネットワークインターフェイスを経由する」ように設定しました。

当時は検証用インスタンスが1つだったので問題なかったのですが、その後検証用インスタンスが2つ以上になったとき、下記の問題が生じ始めたため、何とかしないとなぁという状況になりました。
- 検証用インスタンス1を検証しようと思ったら、ルートテーブルが検証用インスタンス2用に設定されており、上手く検証ができない
- 検証用インスタンス1と検証用インスタンス2を数日ごとに変更しながら検証を行う際、ルートテーブルを変更するのに時間がかかる
この解決策として、EventBridgeで検証用インスタンスが立ち上がったことを検知し、Lambdaで立ち上がった検証用インスタンス用にルートテーブルを動的に変更しよう、となりました。例として、検証用インスタンス2を起動した際の挙動を下図に示します。

解決策の流れ
解決策を実施するにあたり、下記の流れで進めていきました。
- Lambdaを実行する際に用いるIAMロールの作成
- Lambdaの作成
- EventBridgeの作成
- 確認
IAMロールの作成
Lambdaでは、ルートテーブルの変更に加え、CloudWatchログへのロギングも実施します。それに合わせて、IAMロールAWSLambdaBasicExecutionRoleForNWPRoductsを作成します。今回は、それぞれ下記のIAMポリシーをアタッチしています。なお、最小権限で許可したほうが良いので、今回の権限は非常に悪い例です…
- ルートテーブルの変更:AmazonEC2FullAccess
- CloudWatchログへのロギング:下記IAMポリシー
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "logs:CreateLogGroup", "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:log-group:/aws/lambda/*:*" ] } ] }
Lambdaの作成
下記の設定に従ってLambdaに関数Replace-Routesを作成しました。
| 設定項目 | 設定値 |
|---|---|
| 関数の作成 | 一から作成 |
| 関数名 | Replace-Routes |
| ランタイム | Python 3.12 |
| アーキテクチャ | x86_64 |
| 実行ロール | 既存のロールを使用する |
| 既存のロール | AWSLambdaBasicExecutionRoleForNWPRoducts(IAMロールの作成で作成したIAMロール) |
Replace-Routes関数の作成後、一般設定から関数のタイムアウト時間を3秒から30秒に変更しました。下記に記載しているプログラムだと、4~5秒程度かかるようで、タイムアウト時間を延ばさないとタイムアウトによりエラーが発生します。

最後に、作成されたReplace-Routes関数のlambda_function.pyを、下記のように設定して「Deploy」ボタンを押下しました。この時、ルートテーブルIDやプライベートIPレンジ等は各自で修正して利用してください。*1

import os import sys import json import boto3 import pprint from datetime import date, datetime def lambda_handler(event, context): ec2 = boto3.client('ec2', region_name='ap-northeast-1') # get netowk interfaces instances = ec2.describe_instances(InstanceIds=[event['detail']['instance-id']]) instance = instances['Reservations'][0]['Instances'][0] interfaces = instance['NetworkInterfaces'] # get route tables routetables = ec2.describe_route_tables(RouteTableIds=['Public Subnet 2のルートテーブルID', 'Public Subnet 3のルートテーブルID']) # change routes for routetable in routetables['RouteTables']: # extract interface routesubnet = routetable['Associations'][0]['SubnetId'] interface = [i for i in interfaces if i['SubnetId'] == routesubnet] if len(interface) != 1: continue interface = interface[0] #replace routes routes = [i for i in routetable['Routes'] if 'DestinationCidrBlock' in i] for route in routes: if route['DestinationCidrBlock'] in ['10.0.0.0/24', '10.0.1.0/24', '10.0.2.0/24']: response = ec2.replace_route( DestinationCidrBlock=route['DestinationCidrBlock'], NetworkInterfaceId=interface['NetworkInterfaceId'], RouteTableId=routetable['Associations'][0]['RouteTableId'] ) print(json.dumps(response, default=json_serial)) return 0 def json_serial(obj): if isinstance(obj, (datetime, date)): return obj.isoformat() raise TypeError ('Type %s not serializable' % type(obj))
EventBridgeの作成
下記の設定に従ってEventBridgeにルールInstance-Runningを作成しました。なお、ステップ自体は5までありますが、ステップ4(タグを設定)とステップ5(レビューと作成)は何もせず進めています。
ステップ1 ルールの詳細を定義
| 設定項目 | 設定値 |
|---|---|
| 名前 | Instance-Running |
| イベントパス | default |
| 選択したイベントパスでルールを有効にする | 有効化 |
| ルールタイプ | イベントパターンを持つルール |
ステップ2 イベントパターンを構築
| 設定項目 | 設定値 |
|---|---|
| イベントソース | AWSイベントまたはEventBridgeパートナーイベント |
| 作成のメソッド | パターンフォームを使用する |
| イベントソース | AWSのサービス |
| AWSのサービス | EC2 |
| イベントタイプ | EC2 Instance State-change-Notification |
| イベントタイプの仕様 1 | 特定の状態 |
| 特定の状態 | running |
| イベントタイプの仕様 2 | 個別のインスタンスID |
| 個別のインスタンスID | 検証用インスタンスのインスタンスID |
ステップ3 ターゲットを選択
| 設定項目 | 設定値 |
|---|---|
| ターゲットタイプ | AWSのサービス |
| ターゲットを選択 | Lambda 関数 |
| 関数 | Replace-Routes(Lambdaの作成で作成したLambda関数) |
設定の確認
検証用インスタンス1を経由して通信が行われるようにルートテーブルが設定されている状態で、検証用インスタンス2が立ち上がると、ルートテーブルが検証用インスタンス2を経由して通信が行われるように自動で設定されることを確認します。
現在、Public Subnet 2/3のルートテーブルは下記のように設定されています。
- Public Subnet 2のルートテーブル:Public Subnet 1/2/3のプライベートIPレンジが送信先である場合、「eni-07b7~」(検証用インスタンス1のネットワークインターフェイス)へ送付
- Public Subnet 3のルートテーブル:Public Subnet 1/2/3のプライベートIPレンジが送信先である場合、「eni-0299~」(検証用インスタンス1のネットワークインターフェイス)へ送付

この状態で、検証用インスタンス2を立ち上げてしばらくすると、Public Subnet 2/3のルートテーブルが下記のように設定されたため、正常に動作しています。
- Public Subnet 2のルートテーブル:Public Subnet 1/2/3のプライベートIPレンジが送信先である場合、「eni-0dda~」(検証用インスタンス2のネットワークインターフェイス)へ送付
- Public Subnet 3のルートテーブル:Public Subnet 1/2/3のプライベートIPレンジが送信先である場合、「eni-02be~」(検証用インスタンス2のネットワークインターフェイス)へ送付

解決策以外の没案
ここでは、上記の解決策に至るまでの没案を2つほど記載します。
マネージドプレフィックスリストの活用
AWS VPCには、下記のように複数のIPレンジを1つにまとめて定義可能なマネージドプレフィックスリストが存在します。

マネージドプレフィックスリストは、ルートテーブルの送信先としても定義することができる*2上、ルートがランダムに選択されるという記載があったため、下記等のように設定すれば、ランダム性を利用(悪用)してうまく通信できるようになるかと試行錯誤していました。
| 送信先 | ターゲット |
|---|---|
| Public Subnet 1/2/3のプライベートIPレンジを定義したマネージドプレフィックスリスト | 検証用インスタンス1のネットワークインターフェイス |
| Public Subnet 1/2/3のプライベートIPレンジを定義したマネージドプレフィックスリスト | 検証用インスタンス2のネットワークインターフェイス |
・ルートテーブルで複数のプレフィックスリストが参照されていて、異なるターゲットへの CIDR ブロックが重複する場合、優先されるルートはランダムに選択されます。その後は、同じルートが常に優先されます。
しかし、最終的に下記のルールがあることから、どう頑張っても送信先「10.0.0.0/20」のルールが優先されるため、プライベートIPレンジ経由では使えないことが分かりました。
・ルートテーブルに、プレフィックスリストを持つ静的ルートと重複する送信先の CIDR ブロックを持つ静的ルートが含まれている場合、CIDR ブロックを持つ静的ルートが優先されます。
ルーティングプロトコルの活用
RIPやOSPF等のルーティングプロトコルを活用して、検証用インスタンス1が立ち上がっている場合は検証用インスタンス1、検証用インスタンス2が立ち上がっている場合は検証用インスタンス2、をそれぞれ経由する仕組みを作成できないか検討していました。結果として、できないことはないのですが、AWSの費用が高くなってしまうため諦めました。
さいごに
今回の記事のように、AWSでもこういった物理的なネットワーク構成をある程度模倣することが可能です。(物理で考えると、検証用の製品を変更する際にLANケーブルを抜き差しするのが面倒なので、自動でLANケーブルを抜き差しするようにした、みたいなのが今回の記事のイメージです)物理/仮想/クラウド等のどの環境で検証/実装するか、みたいな話は様々な側面で検討する必要があると思いますが、AWSだとAWS Marketplace Subscriptionに存在する各種ライセンスを時間単位の課金で検証できるという利点もあるので、今回の記事のような需要もあるのかな、と思っています。*3
今回の記事のような事例は非常に少ないと思いますが、もし同じような状況に陥った人は参考にしていただければ幸いです。ちなみに、こんなことやらなくても解決できる方法があれば教えてください…
余談
上みたいな感じで個人環境で検証用インスタンスの検証等を行っていたら、11月のAWS費が過去最高になっていました…AWSの使い過ぎには気を付けよう

*1:json_serialは下記リンク先の記事を参考にしています。
https://www.yoheim.net/blog.php?q=20170703
*2:https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/VPC_Route_Tables.html
*3:物理機器だと機器代+年月単位のライセンス代、VMだと年月単位のライセンス代、がそれぞれかかるため、インスタンス関連費+時間単位のライセンス代で済ませられるクラウドは検証も安く済ませられたりします。
Peach FuzzerでTFTPサーバへのファジングを試してみた話
この記事はBoushitsu Advent Calendar 2020 25日目の記事になります。㍆㌋㌉㌏㌉㌸㌾㌋㌞㌹㌅なので、一人寂しく記事を書くことにしました。今回は個人的な備忘録も兼ねて、初心者でもある程度分かりやすいようにPeach Fuzzerによるファジングについて簡単に説明しようかなぁと思いましたが、何故か文字が大量に生えてきました。これ需要ないのでは…タイトルにあるような本題に関係する部分だけ見たい方は、TFTPの仕様を確認するから見ていただくとちょうど本題の部分だけ読み進められると思います。
- はじめに
- 注意点
- ファザー
- ファザーの種類
- Peach Fuzzer
- PITファイルを作成してPeachによるファジングを行ってみる
- TFTPの仕様を確認する
- TFTPサーバに対応したファジングを作成する
- 今後の課題
- おわりに
- おまけ
はじめに
前々からたまに、Peach Fuzzerを改造してわちゃわちゃやっています。そのときに疑問に思ったこと、問題となったことなどがいくつかあったので、需要があるか全く分かりませんが、折角なので自分の知識の整理も兼ねてブログにします。なお、今回実装したコードなどは、全て以下のリンク先にあります。
注意点
今回使用しているのはPeach Fuzzer2系になります。Peach Fuzzer3系関係の記事・ブログなどを閲覧したい方は、本ブログの対象外となります。
また、はてなブログで表示される文字数で27,000文字を超えています。リンクやコードによる部分が大きいとは思いますが、かなりの分量になってしまったので、全部読む場合は少し長いかもしれません。
最後に、今回書いた内容の大半はPeach Fuzzer Community(コミュニティ版のサイト)に書いてありますので、そちらを読むとより良いファジングが行えると思います*1。
ファザー
ファザーとは何かというと、ファジングを行うためのソフトウェアです。では、ファジングとは何かというと、プログラムに対して自動的に生成した大量のデータを生成・送信して、送られたプログラム側の応答や挙動を確認することで、脆弱性診断やテストを行う手法です。要するに、データを生成しまくって、生成したデータを入力しまくって、エラーなどが発生しないか確認するのを機械的に行うものになります。この時、生成されたデータをファズ、データを生成する際に一部の値を変化させることを変異と呼ぶことがあります。ただ、ファズはよく聞きますが、変異はMutation(突然変異)をほぼ直訳したものなので、私が変異だと思って勝手に呼んでいる可能性が高いです…
ファジングによるデータ生成・入力回数がどれくらい早いかというと、例えばintel Core i7–8750Hかつ8GB のメモリのUbuntu16.04上で、AFL(American Fuzzy Lop)*2をとあるプログラムに対してファジングを実行したときには、1秒間に約9,100回データを入力していました。恐るべしファジング…
ファザーの種類
ファザーは、手法や対象とするソフトウェアなどによって、様々な種類に分類されることがあります。自分のブログで申し訳ないですが、以下のリンクなどを参照するとある程度わかってもらえると思います。
詳しく分けていくと、リモートの機器で動作するソフトウェアを対象として動作するリモートファザーなど、もう少し細かく分けることが出来ますが、詳しい説明は割愛します。「色んな種類のファザーがあるんだなぁ…」と思ってもらえれば十分です。
Peach Fuzzer
今回は、既存のファザーとしてPeach Fuzzer*3 (以下、Peachと呼びます)を選択して、Peachに対して新しい変異手法と通信方式を用意した上でTFTPサーバをファジングしようと思います。Peachは、ローカル・リモート問わず、ソフトウェア全般に対してファジングを行うことができます。Peachでは、PITファイルと呼ばれる、様々な情報をXML形式で定義するファイルを用意して、そのファイルの内容に沿ってファジングを行います。
2系と3系
Peachには、Peach2系とPeach3系がありますが、注意点にも記載したように、今回は使用するコードの関係上Peach2系を使用します。ユーザから見たPeach2系とPeach3系と主な違いは、PITファイルの構造や定義可能な要素になりますが、Peach2系におけるPITファイルの定義については後述します。コードから違いを見ると、Peach2系までは主にPythonで書かれており、Peach3系からはC#で書かれています。私はC#が書けないので、今回はPython2で書かれているPeach2系を選択しました。改めて、今回選択したPeachのリポジトリを、下にリンクとして用意しておきます。
PITファイルを作成してPeachによるファジングを行ってみる
Peach2系では、主に5つの要素(XMLヘッダの部分を含めると6つの要素)があります。それぞれの要素を、 下に示したようなcurl http://localhost:8000 を実行した場合のHTTPリクエストヘッダをファジングすることを考えながら、各要素を定義してみます。
GET / HTTP/1.1 Host: localhost:8000 User-Agent: curl/7.54.0 Accept: */*
なお、XMLヘッダは例として次のように定義し、全ての要素はXMLヘッダ内に記載します。
<?xml version="1.0" encoding="UTF-8" ?> <Peach version="1.0" author="著者名" description="説明"> <!-- この中に各要素を記載する。 --> </Peach>
Include
Include要素に指定された別ファイルを読み込みます。自作したプログラムをPeachに組み込まない場合は、ほぼ確実に Peach/Engine/defaults.xmlを読み込むことになります。defaults.xmlで定義されている要素は以下の通りです。
- PythonPath: 新しくPythonのパスを追加する。
- Import: 指定されたパッケージやライブラリを動的にインポートする。
- Mutators(Mutator): インポートされているクラスから、使用する変異手法を定義する。
defaults.xmlをInclude要素で読み込むには、次のような記述をする必要があります。
<Include ns="default" src="file:defaults.xml"/>
DataModel
ファズの元となるデータ構造を定義します。例えば、以下のようなデータ構造の要素を定義できます。
- String: 文字列
- Number: 数値
- Blob: 未定の型やバイナリデータなど
- Relation: StringやBlobなどの子要素となることで、定義した他データ構造の大きさや数値などを取得できます。
- Block: いくつかのデータを一まとめにブロックとして定義することが出来ます。(Block要素を対象とした変異があったり、データ構造の定義に便利だったりします)
また、これらのデータ構造に対しては、isStatic属性やmutable属性を定義することで変異させ内容にしたり、Hint要素を子要素に置いて追加してほしい変異手法を指定したりできます。
String要素を用いて、curl http://localhost:8000のHTTPリクエストヘッダーをDataModel要素で定義する場合、例として次のようなDataModel要素が考えられます。
<DataModel name="HttpRequestHeader"> <!-- 'GET / HTTP/1.1' --> <String name="HttpMethod" value="GET"/> <String name="Space" value=" " type="char"/> <String name="HttpRequestUri" value="/"/> <String name="Space" value=" " type="char"/> <String name="HttpVersion" value="HTTP/1.1"/> <String name="Newline" value="\r\n"/> <!-- 'Host: localhost:8000' --> <String name="HostHeader" value="Host"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="HostValue" value="localhost:8000"/> <String name="Newline" value="\r\n"/> <!-- 'User-Agent: curl/7.54.0' --> <String name="UserAgentHeader" value="User-Agent"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="UserAgentValue" value="curl/7.54.0"/> <String name="Newline" value="\r\n"/> <!-- 'Accept: */*' --> <String name="AcceptHeader" value="Accept"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="AcceptValue" value="*/*"/> <String name="Newline" value="\r\n"/> <String name="Newline" value="\r\n"/> </DataModel>
上の定義は、Block要素などを用いることで、次のようにもう少し綺麗に書くことも出来ます。
<DataModel name="HeaderLine"> <String name="HeaderName"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="HeaderValue"/> <String name="Newline" value="\r\n"/> </DataModel> <DataModel name="HttpRequestHeader"> <!-- 'GET / HTTP/1.1' --> <Block name="RequestLine"> <String name="HttpMethod" value="GET"/> <String name="Space" value=" " type="char"/> <String name="HttpRequestUri" value="/"/> <String name="Space" value=" " type="char"/> <String name="HttpVersion" value="HTTP/1.1"/> <String name="newline" value="\r\n"/> </Block> <!-- 'Host: localhost:8000' --> <Block name="HostHeader" ref="HeaderLine"> <String name="HeaderName" value="Host"/> <String name="HeaderValue" value="localhost:8000"/> </Block <!-- 'User-Agent: curl/7.54.0' --> <Block name="UserAgentHeader" ref="HeaderLine"> <String name="HeaderName" value="User-Agent"/> <String name="HeaderValue" value="curl/7.54.0"/> </Block> <!-- 'Accept: */*' --> <Block name="AcceptHeader" ref="HeaderLine"> <String name="HeaderName" value="Accept"/> <String name="HeaderValue" value="*/*"/> </Block> <String name="newline" value="\r\n"/> </DataModel>
StateModel
どのような手順でファジングを実施するかを定義します。その際、State要素やAction要素といった要素を使用することで、詳細な動作を定義することが出来ます。
- State: 状態を表します。StateModel要素には、最低でも1つ以上の状態が必要です。2つ以上のStateを使用すると、Action要素のchangeStateという動作を使用して状態遷移することもできます。
- Action: State要素内での動作を表します。動作に関しては、例えば以下のようなものがあります。
- input: ファジング対象からのデータを受信します。この時、DataModel要素で定義した受信時のデータ構造が必要となります。
- output: ファジング対象に対してデータを送信します。この時、DataModel要素で定義した送信時のデータ構造が必要となります。
- accept: ファジング対象からの接続を受け付けます。データの送受信方法によってはサポートされていない場合もあります。
- connect: ファジング対象に接続します。ただ、input/outputなどの動作時に、接続されていないと勝手に接続してくれるので、正直あまり使うことはないです。
- close: ファジング対象との接続を閉じます。
State要素やAction要素を用いて、StateModel要素を定義する場合、例として次のようなStateModel要素が考えられます。なお、初期状態を定義するにはStateModel要素のinitialState属性を使用し、Action要素で使用するDataModel要素を指定する場合にはDataModel要素のref属性を使用します。
<StateModel name="HttpRequest" initialState="SendRequest"> <State name="SendRequest"> <Action type="output"> <DataModel ref="HttpRequestHeader"/> </Action> </State> </StateModel>
Test
以下のような要素を使うことで、ファジングを行う場合のテスト環境について定義します。
- Include/Exclude: 変異の対象から追加/除外する要素を定義します。(ここのInclude要素は、先ほど紹介したIncludeとは異なるので注意してください。)
- Agent: その他の要素で紹介するAgent要素を、ref属性を用いてこちらに定義します。
- StateModel: ファジングで使用するStateModel要素を、ref属性を用いてこちらに定義します。
- Publisher: 通信方式について定義します。リモート機器を対象とするなど、相手に関する情報が必要な場合は、Param要素を子要素として以下のような情報を定義します。なお、使用可能な通信方式については、peach/Publishersなどをご覧ください。
- host: 接続先のホスト名・IPアドレスを定義します。
- port: 接続先のポート番号を定義します。
- Strategy: ファジングの変異戦略(どのような変異を行うか、1回のファズ生成につき何箇所変異を行うか、など)を、Strategy要素の属性やParam要素を用いながら定義します。
- Mutator: 使用する変異を改めて定義します。ただし、Mutator要素を定義したTest要素を用いてファジングを実行した場合、defaults.xmlなどで予め追加されている変異は使えなくなります。
各要素を用いて、Test要素を定義する場合、例として次のようなTest要素が考えられます。今回はシンプルにしたいので、Include/Exlucde/Agentは用いません。
<Test name="DefaultTest"> <StateModel ref="HttpRequest"/> <Publisher class="tcp.Tcp"> <Param name="host" value="localhost"/> <Param name="port" value="8000"/> </Publisher> <Strategy class="rand.RandomMutationStrategy" params="MaxFieldsToMutate=4"/> </Test>
Run
実際にファジングを行うための環境を用意します*4。必要であれば、ログを取得する環境を定義することも出来ます*5。通常動作させるRun要素は、DefaultRunという名前をつける必要があります。Run要素の子要素として定義する要素は以下の通りです。
- Test: 別で定義したTest要素を、ref属性を用いてこちらに定義します。
- Logger: ログ環境を定義します。ログ取得のために必要な情報があれば、Param要素を用いて定義する必要があります。
各要素を用いて、Run要素を定義する場合、例として次のようなものが考えられます。今回はシンプルにしたいので、Include/Exlucde/Agentは用いません。
<Run name="DefaultRun" description="Run (HttpRequestHeader)"> <Test ref="DefaultTest"> <Logger class="logger.Filesystem"> <Param name="path" value="Logs/HttpRequestHeader"/> </Logger> </Run>
その他の要素
各要素内で紹介した要素以外にも、以下のような要素があります。全ての要素を知りたい場合は、コミュニティ版のサイトやソースコードをご覧ください。
- Configuration: PITファイル内で使用するマクロとしてMacro要素を定義できます。Configuration要素を上手く使用することで、後述するようなPITファイルの再利用が容易になります。
- Agent: デバッガの接続、ネットワークトラフィックのキャプチャなどを実行することで、Peach実行時の状況を関し可能なMonitor要素を定義できます。
- Data: 定義したDataModel要素内の子要素のvalue属性を定義することが出来ます。定義の方法に関しても、値をそのまま書くだけではなく、ファイルから読み込んだりすることも可能です。
最終的なPITファイル
PITファイルに必要となる要素をそれぞれ説明してきましたが、今回使用するPeach2系では、これらの要素を2つのPITファイルに分けて使用することが推奨されています。もちろん、1つのPITファイルのみで全ての記載を行うことも可能ですが、その場合PITファイルの再利用が難しくなります。本ブログでは、推奨されているPITファイルを2つに分ける方法を採用します。また、2つのPITファイルのことを、それぞれFile PITファイル、Target PITファイルと呼んでいきます。それぞれに記載する必要のある要素は以下の通りです。
- File PITファイル: ファジングを行うための仕様(変異手法の種類、データ構造)を定義します。こちらには、XMLヘッダ、Include要素、DataModel要素の3つを定義します。
- Target PITファイル: ファジングを行うための環境を定義します。こちらには、XMLヘッダ、StateModel要素、Test要素、Run要素の4つを定義します。
最終的に作成したFile PITファイルとTarget PITファイルは、以下の通りです。
<!-- File PITファイル --> <?xml version="1.0" encoding="UTF-8" ?> <Peach version="1.0" author="who3411" description="curl HttpRequestHeader"> <!-- Include要素 --> <Include ns="default" src="file:defaults.xml"/> <!-- DataModel要素 --> <DataModel name="HttpRequestHeader"> <!-- 'GET / HTTP/1.1' --> <String name="HttpMethod" value="GET"/> <String name="Space" value=" " type="char"/> <String name="HttpRequestUri" value="/"/> <String name="Space" value=" " type="char"/> <String name="HttpVersion" value="HTTP/1.1"/> <String name="Newline" value="\r\n"/> <!-- 'Host: localhost:8000' --> <String name="HostHeader" value="Host"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="HostValue" value="localhost:8000"/> <String name="Newline" value="\r\n"/> <!-- 'User-Agent: curl/7.54.0' --> <String name="UserAgentHeader" value="User-Agent"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="UserAgentValue" value="curl/7.54.0"/> <String name="Newline" value="\r\n"/> <!-- 'Accept: */*' --> <String name="AcceptHeader" value="Accept"/> <String name="Colon" value=":" type="char"/> <String name="Space" value=" " type="char"/> <String name="AcceptValue" value="*/*"/> <String name="Newline" value="\r\n"/> <String name="Newline" value="\r\n"/> </DataModel> </Peach>
<!-- Target PITファイル --> <?xml version="1.0" encoding="UTF-8" ?> <Peach version="1.0" author="who3411" description="curl HttpRequestHeader"> <!-- StateModel要素 --> <StateModel name="HttpRequest" initialState="SendRequest"> <State name="SendRequest"> <Action type="output"> <DataModel ref="HttpRequestHeader"/> </Action> </State> </StateModel> <!-- Test要素 --> <Test name="DefaultTest"> <StateModel ref="HttpRequest"/> <Publisher class="tcp.Tcp"> <Param name="host" value="localhost"/> <Param name="port" value="8000"/> </Publisher> <Strategy class="rand.RandomMutationStrategy" params="MaxFieldsToMutate=4"/> </Test> <!-- Run要素 --> <Run name="DefaultRun" description="Run (HttpRequestHeader)"> <Test ref="DefaultTest"/> <Logger class="logger.Filesystem"> <Param name="path" value="Logs/HttpRequestHeader"/> </Logger> </Run> </Peach>
なお、Pitsディレクトリ内を確認すると、FilesディレクトリとTargetsディレクトリに、それぞれFile PITファイルとTarget PITファイルの例があります。各ディレクトリの例では、Configuration要素やAgent要素に関する例もありますので、自分でPITファイルを書きたい方は、こちらもあわせて確認すると良いです。
実際にファジングしてみる
最終的なPITファイルで作成したFile PITファイルとTarget PITファイルを用いて、Python2のSimpleHTTPServerに対して、実際にファジングを行ってみます。なお、インストールなどに関しては各自README.mdのSetupをご確認ください。
作成したPITファイルはcurl http://localhost:8000を実行した場合のHTTPリクエストヘッダーを生成してファジングを行うので、これに合うようにSimpleHTTPServerを動作させるには、以下のコマンドを使用します。
# Python2の場合 $ python -m SimpleHTTPServer 8000 # Python3の場合 $ python -m http.server 8000
上のコマンドを用いて立ち上げたSimpleHTTPServerに対して、新しくターミナルを立ち上げて、実際にPeachによるファジングを行いながらSimpleHTTPServerとファジングの出力を確認します。Peachによるファジングでは、下のコマンドのようにFile PITファイルとTarget PITファイルを、それぞれpitオプションとtargetオプションで指定します。なお、それぞれのファイルは、冒頭で紹介したリポジトリにも含まれています。
$ python peach.py -pit Pits/Files/httprequestheader.xml -target Pits/Targets/simplehttpserver.xml
コマンドを入力すると、凄い勢いで文字列が流れていくと思います。また、SimpleHTTPServerを立ち上げていた方を見ると、そちらも凄い勢いで文字列が流れていると思います。実際に大量のリクエストを送信していることが実感できたでしょうか。
TFTPの仕様を確認する
前置きがはてなブログで表示される文字数で15,000文字弱とかなり長くなってしまいましたが、ようやく本題のTFTPサーバのファジングに移ります。ただし、TFTPの仕様がどのようなものであるか分からないと、上手くファジングを行うことが出来ません。そのため、まずは今回の対象とするTFTPについて確認していきます。なお、TFTPに限らず、Peachを用いて新しい対象のファジングを行う場合、大抵は以下のような流れになると思います。
- 対象の仕様(データ構造、シーケンスなど)を理解し、ファジングを行うための方針を策定する
- (必要であれば)追加で変異手法(Mutator)や通信形式(Publisher)を作成する
- この場合、PITファイルには新しく作成したMutatorやPublisherも対応できるようにする
- 対象に合ったPITファイルを作成する
TFTPとは
TFTPを雑に説明すると、認証機能の存在しないUDPで動作するFTPのようなものです。UDP上で通信が行われるので、TCPコネクションの確立などのオーバーヘッドを必要とせず、簡単な再送処理を行うことも出来ます。
TFTPでは、データのアップロードとダウンロードにおいて、それぞれ以下の図のような手順でデータを転送します。図のうち、until~の部分はデータ転送が終了するまでループします。
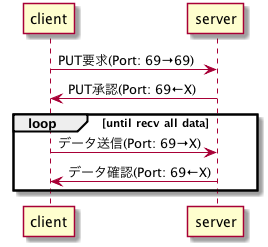
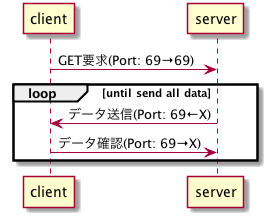
TFTPのコマンド
今回ファジングを行う際のTFTPでは、RFC1350で定義されている5つのコマンドが存在します。
- RRQ: データのダウンロード要求
- WRQ: データのアップロード要求
- DATA: 実際に送信されるデータ
- ACK: 要求に対する承認
- ERROR: エラーの内容
5つのコマンドのうち、はじめにTFTPクライアントからTFTPサーバへ送信するコマンドは、RRQかWRQの2つになります。そのため、今回はRRQとWRQの2つをファジングできるようにPITファイルを定義しようと思います。
RRQとWRQのコマンドに関して、それぞれのフォーマットは以下の図のようになっています。下の図のうち、データの区切りのためにある文字を除くと、
- Opcode: コマンドの番号(0x0001ならRRQ、0x0002ならWRQ)
- Filename: データ転送を行うファイル名(RRQならTFTPサーバ上にあるファイル名、WRQならTFTPサーバ上にアップロードするファイル名)
- MODE: 転送モード(octet、netascii、mailの計3つあるが、今回使用するソースコードの関係上、あまり気にしなくていい。多分octetが一番使われている)
の3つのパラメータがあることがあります。なので、RRQとWRQをファジングできるようにするには、opcodeだけを変えることで達成できます。また、変異を行うデータに関しては、Opcode、Filename、MODEの3つで大丈夫そうです。
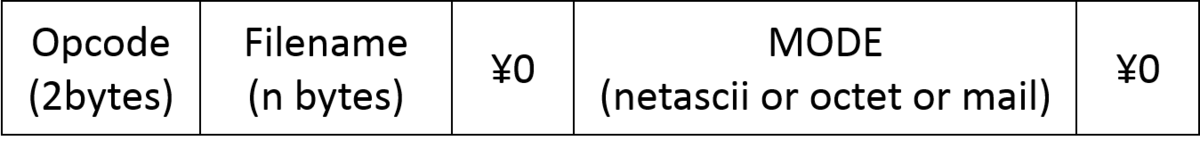
なお、RRQとWRQ以外のデータ構造の詳細に関して知りたい方は、RFC1350のAppendixにあるTFTP Formatsを参照してください。
ファジングを行う上でのTFTPの問題点
今回のファジングを行う上で問題になりそうなのは、以下の3点になります。
- ポート番号の変更: TFTPでは、UDP69番ポートへのリクエストの後、別のポートからデータ転送を行います。この場合、今まで説明してきた方法ではポート番号を変更することができないので、対処する必要があります。
- データ転送時のファイル分割: TFTPでは、データ転送を行う際、512バイトごとに区切ったデータを転送し、都度データが転送されたことを伝えるレスポンスが返ってきます。この時、512バイトごとに区切ったデータを転送する、という変異手法はないので、こちらも対処する必要があります。
- ファイル名をランダムに返す変異がない: Peachには、ファイルに記載された文字列を、上から1列ずつ返す変異手法が存在します。これを利用することで、ファイル名を返す変異を作成することは可能です。ただし、ディレクトリ内にあるファイル名を返す変異や、ファイルに記載された文字列をランダムに返す変異などは存在しないので、そういった変異を行う際には自作する必要があります。
今回は、これらの問題点をMutatorとPublisherを追加することで解決しようと思います。
TFTPサーバに対応したファジングを作成する
TFTPの仕様を確認するで確認した情報などを元に、TFTPサーバのファジングの仕様と、実施に必要となる修正内容をそれぞれ下に記載します。
- 仕様
- TFTPクライアントから送信されるWRQとRRQのコマンドをPITファイルで生成・送信できるようにする。
- (PITファイルを作成してPeachによるファジングを行ってみるでは簡略化のためしていなかったが、)それぞれの通信のレスポンスや、追加のリクエスト・レスポンスを受け取る。
- 修正内容
- 通信の途中で発生するポート番号の変更、データ転送時のファイル分割など、PITファイルで上手く対応できない箇所を、Publisherの追加によって解決する。
- ファイル名をランダムに返す変異が存在しないため、そのような変異を作成する。
まずは、修正内容に従って、Publisherを変異手法をそれぞれ追加します。
Publisherの追加
ファジングを行う上でのTFTPの問題点の問題点1,2に対処するため、TFTP通信を行ってくれるPublisherを作成します。
Publisherを追加する場合、一から自作したり、既に存在するライブラリなどを使用したり、いくつか手法はあるかと思いますが、今回は既に存在するライブラリのtftpy*6を使おうと思います。
tftpyについて
tftpyは、2,000行程度と小規模なPython製のライブラリで、RFC1350を含めたTFTP通信をサポートするライブラリです。実装されているTFTPクライアントでは、download(RRQ)とupload(WRQ)のメソッドを使うことができます。
それぞれのメソッドは、次のように使うことが出来ます。
import tftpy client = tftpy.TftpClient('tftp_server_addr', 69) client.download('remote_filename', 'local_filename') client.upload('local_filename', 'remote_filename')
tftpyをファジングに使えるようにする
downloadとuploadだけでは、ファズを上手く送信することが出来ないので、新しくrawdataというメソッドを追加しました。rawdataでは、RRQ/WRQコマンドで変更可能なパラメータであるopcode、filename、modeを全て受け取り、それ以降の通信を全て行ってくれます*7。
また、tftpyでは、エラーが発生するとディスクリプタを閉じないままプログラムが終了してしまいます。リクエストを大量に送信し、リクエストごとにエラーの発生する確率の高いファジングでは、ディスクリプタを閉じないままリクエストを送信し続けることで、そのうちディスクリプタが枯渇してしまいます。このような問題を解決するため、エラー発生に関わらず必ずディスクリプタを閉じるようにしました。
更に、TFTP通信を行うと、どうしてもファイルが増えてしまうため、ファイルをダウンロードできないように、ダウンロード時の書き込み先ファイルを/dev/nullにしました*8。
最終的に、次のような形式でrawdataメソッドを使えるようにしました。
import tftpy client = tftpy.TftpClient('tftp_server_addr', 69) # client.rawdata(opcode, filename, mode) client.rawdata("\x00\x01", "filename", "octet") #download client.rawdata("\x00\x02", "filename", "octet") #upload
実装の詳細は以下のリンクのtftpy/TftpClient.pyとtftpy/TftpContexts.pyをご覧ください。
新しいPublisherとしてTftpを追加する
修正したtftpyを使って、新しいPublisherのTftpを追加します。Publisherを追加する際の方法は、コミュニティ版サイトのCreate a Custom Publisherにも説明があります。今回は、少しでも楽をしたい上手くtftpyに追加したrawdataメソッドを使いたいので、PublisherのsendWithNodeメソッドを使います。
sendWithNodeメソッドでは、DataModel要素のデータ構造をそのまま受け取ることが出来ます。つまり、「DataModel要素内のname属性の値がfilenameのString要素の値(ファズ済み)を取得する」といったことができるようになります。標準で用意されているPublisherではほとんど使われていませんが、自分でカスタマイズしてPublisherを作成する際には非常に便利なメソッドになります*9。
実際のsendWithNodeメソッドの実装は以下の通りです。param_listに格納した名前の要素の値(opcode, filename, mode)を取り出して、その値をtftpyのrawdataメソッドに突っ込むだけという簡単な実装になっています。ちなみに、実際にファジングを行う際には例外処理を細かく指定するのですが、今回は簡略化しています。
def sendWithNode(self, data, dataNode): ''' Publish some data @type data: string @param data: Data to publish @type dataNode: DataElement @param dataNode: Root of data model that produced data ''' params = dict() param_list = ["opcode", "filename", "mode"] for child in dataNode.getAllChildDataElements(): if child.name in param_list: if child.get_Value() is None: params[child.name] = "" else: params[child.name] = child.get_Value() try: self.client.rawdata(params["opcode"], params["filename"], params["mode"]) except KeyboardInterrupt: raise except: pass
後は初期設定などを簡単に指定して新しいPublisherを作成しました。詳細な実装は以下のリンク先をご覧ください。
peach/tftp.py at support_tftp · who3411/peach · GitHub
Mutatorの追加
ファジングを行う上でのTFTPの問題点の問題点3に対処するため、ファイル名をランダムに返す変異を作成します。
Peachには、予めファイルに記載された文字列を上から1列ずつ返すDictionaryというデータ生成手法が存在するので、今回はそれを使います。Dictionaryに使用するファイルには、予めTFTP通信で使用するファイル名を記載しておく必要はありますが、この方が楽々に仕上げられる汎用性の高いデータ生成手法になります。
Dictionaryの改良
Dictionaryでは、ファズを生成するたびに1列ずつファイルを読んで返しているだけなので、今回は次のような手順でランダムに返すように改良しました。
- 最初にファズを生成する際に、ファイル内のデータを全て読み、1列を1要素としたリストにしておく。
- ファズの生成時、リストにしたデータからランダムに1つだけ返すようにする。
上のような手順になるようにDictionaryを継承して、新しくRandomDictというデータ生成手法を追加しました。詳細な実装は以下のリンク先をご覧ください。
peach/randomdict.py at support_tftp · who3411/peach · GitHub
新しいMutatorとしてDownloadFileListMutatorとUploadFileListMutatorを追加する
Dictionaryを改良したRandomDictを使って、新しいMutatorを作成します。今回はダウンロード時のコマンドとアップロード時のコマンドで、それぞれ別のファイルパスを指定したいので、ダウンロード用の変異手法としてDownloadFileListMutator、アップロード用の変異手法としてUploadFileListMutatorをそれぞれ用意します。
幸い、Peachの変異手法には、Dictionaryを使用した変異手法である_SimpleGeneratorMutatorがあるので、これを利用してFileListMutatorを作成します。FileListMutatorは、_SimpleGenetorMutatoと比較して、データ生成手法をRandomDictにして、ランダムな変異を追加しただけの簡単な変異手法です。
次に、FileListMutatorを元に、DonwloadFileListMutatorとUploadFileListMutatorを作成します。それぞれの変異手法を使用する際に参照されるファイルは、Tftp/downloadFileList.txtとTftp/uploadFileList.txtに置くように設定しました。なお、今回のようなあまり汎用的ではないMutatorは、変異可能な要素を可能な限り抑えたいので、MutatorのsupportedDataElementメソッドを使って、変異可能な要素を限定します。
限定する条件は以下の3つです。
- String要素である。
- 変異可能な要素である。
- 子要素にHint要素があり、特定の属性を有している。
例えば、DownloadFileListMutatorのsupportedDataElementメソッドは、次のようになっています。
def supportedDataElement(node): if isinstance(node, String) and node.isMutable: for child in node.hints: if child.name == 'type' and child.value == 'downloadfilelist': return True return False
これでMutatorの追加も終わりです。詳細な実装は以下のリンク先をご覧ください。
peach/filelist.py at support_tftp · who3411/peach · GitHub
PITファイルの作成
作成したPublisherとMutatorを使って、新しくTFTPサーバをファジングするためのPITファイルを作成します。と言っても、全て解説すると長くなってしまうので、Include要素とDataModel要素について説明します。
Include要素における注意点
HTTPヘッダの方ではIncludeの対象をdefaults.xmlとしていましたが、今回は独自で作成したプログラムがあるので、それらを含める必要があります。そのため、defaults.xmlを今回にあわせて修正したdefaults-tftp.xmlを用意し、それをIncludeの対象としました。
注意点として、Include要素の後で新しくMutators要素を定義したり、Test要素内でMutator要素を定義したりすると、前に定義したMutators要素が上書きされてしまいます。そのため、Mutators要素を定義する際には、必ず自分が定義したいMutatorを全て定義しておくようにしてください。
DataModel要素とtftpyの連携
新しいPublisherとしてTftpを追加するで説明したように、今回はDataModel要素内で、name属性がopcode、filename、modeである要素をそれぞれ1つずつ用意する必要があります。今回はRRQコマンド、WRQコマンド、その他のコマンドの3つのDataModel要素を定義しましたが、どれもopcode、filename、modeを含んでいます。
最終的なTFTP用PITファイル
最終的に作成したPITファイルは、
- Tftp/defaults-tftp.xml: defaults.xmlをTFTPサーバのファジング用に修正したもの
- Pits/Files/tftp.xml: File PITファイル
- Pits/Target/tftpy.xml: Target PITファイル
の3つになります。それぞれのリンク先を下に置いておきます。
- peach/defaults-tftp.xml at support_tftp · who3411/peach · GitHub
- peach/tftp.xml at support_tftp · who3411/peach · GitHub
- peach/tftpy.xml at support_tftp · who3411/peach · GitHub
実際にファジングしてみる
最終的なTFTP用PITファイルで作成したFile PITファイルとTarget PITファイルを用いて、tftpyのTftpServerに対して実際にファジングを行ってみます。なお、TFTPServerを立ち上げる際のPythonコードは、以下のとおりです。
import tftpy server = tftpy.TftpServer("tftp server root directory") #TFTPサーバにとってのルートディレクトリを引数としてください。 server.listen("0.0.0.0", 23456) #well-known portは通常Permission Deniedが出るので、適当に23456としました。
上のコードを用いて立ち上げたTftpServerに対して、新しくターミナルを立ち上げて、実際にPeachによるファジングを行いながらファジングの出力を確認します。Peachによるファジングでは、下のコマンドのようにFile PITファイルとTarget PITファイルを、それぞれpitオプションとtargetオプションで指定します。なお、上のPythonコードと違う方法でサーバを立ち上げたりした場合は、Pits/Target/tftpy.xmlのPublisherのhostとportを自身の環境に合うように変更してください。
$ python peach.py -pit Pits/Files/tftp.xml -target Pits/Targets/tftpy.xml
ファジング側の出力を見てみると、DownloadFileListMutatorやUploadFileLitMutatorが動いていること、実際にデータのやり取りが行われいてることなどがわかります。使用している変異手法が見えるようにしたターミナルの出力を一部以下に貼り付けます。
[Peach.root] Performing mutation. [Peach.root] DownloadFileListMutator => filename [Peach.root] UnicodeBadUtf8Mutator => mode [Peach.root] BitFlipperMutator => N/A [Peach.root] Mutation finished. [Peach.tftpy.TftpContext] Sending tftp rawdata request to localhost [Peach.tftpy.TftpContext] filename -> bluetooth.py [Peach.tftpy.TftpContext] options -> {} ... [Peach.root] Performing mutation. [Peach.root] UploadFileListMutator => filename [Peach.root] Mutation finished. [Peach.tftpy.TftpContext] Sending tftp rawdata request to localhost [Peach.tftpy.TftpContext] filename -> Peach/Publishers/wifi.py [Peach.tftpy.TftpContext] options -> {}
また、上ではTftpServerを対象としましたが、他にもRaspberry Pi上で動作するatftpdに対してもファジングを行ってみました。ファジング実施時のパケットをキャプチャしたところ、下の図のようになりました。実際にデータをやり取りできていることや、エラーが発生していることなどがわかると思います。

今後の課題
今回はtftpyを使ってTFTPサーバへのファジングを行いましたが、TFTPサーバへのファジングをもっと厳密に行うには、
- はじめのリクエスト以外の部分もファズを生成できるようにする
- TFTPサーバからのレスポンスも詳しくチェックする
- はじめのリクエストにおいてRRQ/WRQ以外のフォーマットのファズも生成・送受信できるようにする
などの課題が残っています。今回はTFTPサーバへのファジングを簡単に行うために、色々と制限をつけてある程度簡単にファジングを行えるようにしましたが、この辺りの課題を詰めていくともっと面白いかもしれません。
おわりに
果たしてここまで上から飛ばさずに読んでくれた方はいるのだろうか…私なら絶対に飛ばす…
Peachについて、おそらくユーザが一番使用することになるPITファイルを簡単に紹介して、本題であるTFTPサーバへのファジングを試してみました。本当はもっとサーバを追い込んで問題を発生させたり、問題が発生したと思われる入力を絞り込んで検証していったりするのですが、そこまで書くと文字数が大変なことになってしまうし期日中に記事が出来なくなってしまうので、ここまでとさせていただきます。
私がPeachを本格的に触ろうと思った頃は、PITファイルが意味不明で分からず、カスタマイズしようにもコミュニティ版のサイトがなぜか403エラーで読めなかったので地獄でした。今はサイトも復活してますし、ブログや記事も充実してきているので、Peachもやりやすくなったのではないかなぁ、と感じています。ただ、今回のようなMutatorやPublisherをカスタマイズする際の注意点、実際にカスタマイズを行った上でファジング、sendWithNodeメソッドを使ったデータの送信など、個人的にやりたい部分はまだまだ手探りで進めないと厳しい部分があると感じます。もちろん初心者でも上から読めばある程度は理解できるように記事を作ったつもりですが、今回の記事の内容が上手く行かずに困っている人にも見ていただければ幸いです。
最後に、Advent Calendar最終日にこんな長文の怪文書を作成してしまい大変申し訳ありませんでした。もし来年以降参加する機会があれば、もう少し文字数を減らすように努力しようと思います。ありがとうございました。
おまけ
ここまでPeachを使ってTFTPサーバのファジングを行いましたが、もちろんこれらを行っていく上で、PITファイルの作成で問題が発生したり、痒いところに手が届かなかったり、そういった状況があると思います。個人的にそのような状況に陥った際のごり押し解決方法をいくつか紹介したいと思います。
なお、おまけで紹介する解決方法は大体がPeachのコードを直接いじるものになっているので、正直非推奨な方法が多いです。ご注意ください。
特定の要素だけ変異手法を制限したい
defaults.xmlを使って様々な変異手法を入れたはいいものの、例えば「name=filenameのString要素は、今回実装したDonwloadFileListMutatorのみを変異手法として追加したい」みたいな状況がたまにあります。こういうとき、PITファイルを使って上手く解決することが出来ないのですが、コードを書き換えて無理やり解決することが出来ます。
Peachでは、初めに要素ごとに実行可能な変異手法を調べ、その結果を元に要素ごとに変異手法を用意します。この処理は変異手法をどのような流れで行うかを制御する変異戦略によって行われます。変異戦略関係のコードはPeach/MutateStrategies以下にあります。今回は、変異戦略のうち、ランダム戦略であるrand.pyにおいて、最初に書いた状況に合致するようなコードを書いてみます。
rand.pyを読んでみると、270行目から279行目において、全ての要素で実行可能な変異を調査・用意していることが分かります。例えば、279行目を以下のようなコードに書き換えることで、特定の要素だけ変異手法を制限することが出来ます。
mut = m(Engine.context, node) if node.name.find("filename") >= 0: if mut.name.find("DownloadFileListMutator") < 0: continue mutators.append(mut)
コードの修正前後で、name=filenameのString要素に用意される変異手法は、次のように変化します。
# 修正前 DataTreeRemoveMutator DataTreeDuplicateMutator DataTreeSwapNearNodesMutator StringMutator FilenameMutator StringCaseMutator UnicodeBomMutator UnicodeBadUtf8Mutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator UnicodeUtf8ThreeCharMutator DownloadFileListMutator # 修正後 DownloadFileListMutator
これが何に役立つかというと、例えばDownloadFileListMutatorは実際に動いているのか確認する場合に結構役立ちます。
DataModel要素を消されないようにしたい
Peachでは、DataModel要素がデータ構造のトップレベルの要素として認識されている一方、DataModel要素自体も変異の対象となります。そのため、BlobやDataTree関係の変異手法が用意され、場合によっては空文字列になったりします。すると、Publisherのsendメソッドで空文字列が送られてくることになることがあります。
DataModel内の各要素はisStatic属性やmutable属性を使うことで、各属性がtrueの要素は変異を行わないようにできますのですが、DataModel要素自身はその属性を付与することが出来ません。そこで、コードの方からDataModel要素に対する変異手法を用意できないように修正することで解決することが出来ます。
こちらも変異戦略関係の問題なので、rand.pyのコードを変更します。rand.pyの268行目を見ると、nodes.append(dataModel)というコードがあると思います。これがDataModel要素を実行可能な変異手法の調査・用意を行うための準備なので、この行を削除します。このままでも解決しますが、一応変異しないノードを追加しておくnonMutableNodesにdataModelを追加すると、より丁寧になります。
*1:私がPeach Fuzzerをいじってた最初の頃、何故かコミュニティ版のサイトが403が出て閲覧できなくなっていたので、もしかしたら見れなくなっているかもしれません
*2:最近だとIPAからAFLの実践資料が公開されています。詳しくはこちら。
*4:脚注3の資料では、Peach2系のRun要素について、「詳細情報: なし」としていますが、実際はhttps://community.peachfuzzer.com/v2/Run.htmlにあります。
*5:脚注3の資料では、Peach2~3系において、Test要素にログの出力先などを定義できるとありますが、実際は、Peach2系ではRun要素でログの出力先を定義する必要があります。今回使用するコードを確認すると、Run要素の解析を行うHandleRunメソッド内にログ関係の定義を行うLogger要素の解析部分があります。
*6:ドキュメントはhttp://tftpy.sourceforge.net/sphinx/index.htmlにあります。
*7:tftpyは、TFTP通信に存在する3つの通信モードのうち、octetモードにしか対応していないので、実は別のモードを試せなかったりします。今後の課題です…
*8:ひどい時はディレクトリ内に1000ファイル溜まったりして苦しんでました…
*9:sendメソッドでTFTP通信を何とかしようとしたら、一切加工/注釈付けされていないファズを無理やりパースして使わないといけないので、非常に面倒です。というかデータ生成時点で、ほとんどのデータの変異を禁止しておくなど、何らかの工夫をしておかないと確実に上手くパースできません。
第15回情報危機管理コンテストに参加しました
この記事はBoushitsu Advent Calendar 2020 10日目の記事になります。といいながら、実はこの記事、多分作成してから6ヶ月たっているものになります…。(「Advent Calendarの季節だなぁ…」と思ってなんとなく記事の管理を見てみたら、下書き状態で丸ごと記事が一つ残っていました)誰だコンテスト終わったら急いで書いて公開するって言ってた奴は…
というわけで、以下、残っていた記事になります。少し長いですがお付き合いいただければ幸いです。
はじめに
2020年4月から5月にかけて、第15回情報危機管理コンテストにチーム「sawayaka-sec A」として参加しました。(第14回情報危機管理コンテストにもチーム「sawayaka-sec A」として参加していたのですが、第14回の時は2次予選で落ちました。)
情報危機管理コンテストの内容については、以下の公式サイトに詳しく書いてあります。
また、第13回情報危機管理コンテストに参加していた時のブログもこちらに貼っておきます。
注意点
どこまで公開していいかわからないので、具体的なこと(「コンテストで使用するサーバの〇〇というソフトウェアが〜」など)は述べないようにします。ただしネットで少し検索すればわかるような内容については記述しようと思います。
参加したきっかけ
第13回に参加していた頃は、コンテスト自体に興味があり、かつ参加してくれそうな人がいたので、ただただ楽しく参加していました。ただ、折角決勝まで参加できたのに、コンテストのために学んだ知識や蓄えたノウハウを後輩に伝えずに終わるのは勿体無いし、コンテストに参加するのに加えて少しでもセキュリティに興味を持ってもらえる人が増えて欲しいなぁ…と思っていました。
そんなこんなで、第14回からは経験者と初参加者を混ぜた2チーム体制をとり、初参加者に少しでもセキュリティインシデントについて学んでもらえるように努力しました。(と言っても私は告知や事務作業などを行っていただけなので、私以外の人がチームメンバーの大半を集めてくれました。)チームメンバーを集めてくださった方、参加してくださったチームメンバーの方たちに圧倒的感謝っ・・・・!
参加までの話
とりあえず今年も参加することを告知して、チームメンバーを集めていました。コンテストは2~4人チームなので、8人(2チーム×4人)集まってくれるとうれしいと思っていたら、本当に8人集まりました。この辺りは先述したようにチームメンバーの方のおかげです。
それからは初参加者に向けて、改めてコンテストに関しての説明を行い、経験者と初参加者が混ざるように2チームの編成を組みました。ちなみに、今年は異なる4つの学年が2人ずつ集まったので、各学年バラバラのチームを組みました。
一次予選
一次予選までにやったこと
とりあえずこれまでに作った一次予選用の資料を共有したり、予選の流れなどの簡単な説明を行ったりしていました。過去2年と違う点としては、567の影響もあって全員遠隔で行ったことですね。おのれ567…
後は過去のブログにも書いているように、過去問のチェック、集まる時間、問題の解答手順などを決めました。
一次予選中の話
一次予選中は、予め決めていた手順に沿って考えていきました。これまでは非常に悩んで競技時間中の深夜まで問題について話し合うことがあったのですが、今年は何故かスムーズに進んで逆に不安になりました。ただ、これまでの問題と比較して、一部旨く判断のつかない部分があったり、回答方法に悩んだりした記憶があります。
結局2日で回答の大まかな流れを決めて、作成する文章の割り当てをしました。作成した文章も校正する時間があったので、やはり今年は結構時間に余裕があったと思います。ただ、途中でチームメンバーが反則行為になるかならないか微妙な脆弱性をついてしまったときは笑ってしまいました冷や汗をかきました(ちゃんと運営にお詫びを入れました。)
二次予選
一次予選から数日後、一次予選突破を受けて、本格的に二次予選へと足を運ぶ形になりました。
二次予選までにやったこと
二次予選は実戦形式でトラブル対応を行うため、まずは使用するOSやソフトについて調べるとともに、実際に仮想環境などを用意して動かしたりしていました。私は普段からサーバを弄ったりCUIで生きていたりするような人間ではないため、余り実践的な知識はありません。なので、調べた内容をまとめたり、用意した仮想環境で実際に動かしたりしながら、少しでも役に立てるよう本番に備えました。
また、情報危機管理コンテスト関係の記事や参加者のブログなどを眺めたり、昨年までの二次予選に参加した際の内容を見返したり、簡単な二次予選用の資料を作って共有したりしました。二次予選からは過去問などは配布されていないため、基本的には問題を想像しながら対策を行う必要があります。ただ、二次予選から山を張るようなことはできないと思うので、参加したからといって、「ここ絶対出るから対策しておこう」みたいなことはあまりできません。
あと、役割分担を決めました。何事も役割分担通りには行かないことが多いですが、とりあえず基本的に何をやるか、程度は決めておくと良いです。ちなみに、私はトラブル対応の報告書作成、顧客や上司へのメール作成など、トラブル対応以外の部分を主にやりました。
ちなみに、今年度特有のものとして、音声チャットなどを使ったオンライン参加か、大学などの場所で集まって参加か、どちらにするかを決めました。決めると言ってもこの辺りは学生だけでは決められない内容なので、指導教員などと相談しながら決めていきました。結局オンライン参加になりました。おのれ567…
二次予選中の話
協議の内容は詳しくいえないので省略しますが、「sawayaka-sec A」は1つ目のシナリオを解いて、2つ目のシナリオの原因が分からないまま競技が終了しました。1つ目のシナリオは速攻で分かったのに、2つ目は全然分からないで終了したのは流石に悔しかったです。正直、競技終了時点だと「あぁ…今年はここで終わりか」と思ってました。
終わった後で運営側の方と少し話をして原因を聞いたときは、「あ~…ローカルなら速攻で原因わかってそうな問題だ…」となっていました。しかも、私はもう少しで原因が分かるところまできていた(原因が分かる情報を収集できていた)のに分かってなかったので、本当に悔しさと情けなさで申し訳なかったです。
決勝戦
二次予選が終わった数時間後、本戦出場チームへの連絡っぽいメールが来ていました。が、二次予選が出来てなさすぎて「どうせ誤報だ」と思いながら寝ました。しかし、目が覚めたら公式に決勝戦へ進めることになっていました。なお、今回は決勝戦も二次予選と同様にオンライン開催になったので、白浜へ行って観光する競技するという楽しみがなくなってしまいました。おのれ567…
ちなみに、決勝戦が終わった後に聞いた話ですが、「決勝戦へ進んだチームの中だと最下位だった」と言われました。まさに奇跡…
決勝戦までにやったこと
今年は某企業のサービスを使うことになったので、そのセミナーを聞くことになりました。普段では絶対に使わないようなサービスを使えるということもあって、色々と面白かったです。(余談ですが、セミナー中に各チームから一言意気込みのようなことを話すことになっていたのですが、とあるチームの意気込みが強すぎてなんか凄かったです(語彙力))加えて、決勝戦もオンライン参加になることもあって、全チームがオンラインで集まって協議を行うことになりました。全チームが集まるといっても、チームごとにブレイクアウトルームへ入るので、他チームの型と交流することは基本的にありません。
あとは基本的に二次予選とほぼ同じです。現地での競技ではなくなったので、ネットワーク機器用のケーブルや延長コードなどを用意する必要がなかったのは楽でした。
決勝戦中の話
決勝戦はライブ中継されていて、また中継の内容を分割した動画も上がっています。詳しくは以下のリンク先をご覧ください。
第15回情報危機管理コンテスト決勝戦 動画リスト( #sccs2020 / #cmc15th ) - YouTube
競技は午前と午後に分かれていて、それぞれ別のシナリオとして問題が進められていきます。
相変わらず詳しい内容は言えないのですが、午前は1つ目のシナリオを解いて、2つ目のシナリオを解決するであろう策を講じたところで終わりました。2つ目のシナリオは、後でライブ中継を眺めていたら原因が話されていて、上司に殺意が沸きましたこの原因突き止めるの難しいなぁ…と思いました。
そんなこんなで午前中は中途半端に終わってしまったところで、気合を入れる(?)ために某さ○やかのさわ○かハンバーグをチーム全員で共有して午後に臨みました。

午後は1つ目のシナリオを解いて、2つ目のシナリオを解決する策を見つけたところで終わりました。午後に関しては原因も全て分かった上で解決途中で終わったので、午前よりは満足の結果で終わったです。
結果
決勝が終わって2日後の6月1日の午前中に結果発表がありました。各チームの賞は以下の通りです。( 決勝戦についての決勝戦結果発表の内容のうち、個人名と大学名関係の記述を省略して貼り付けています。省略したのは、個人名や大学名の名前をブログに載せることに少し違和感を感じたためです。)
上記の通り、「sawayaka-sec A」は経済産業大臣賞を受賞させていただきました。弊学から参加したチームとしては、昨年に引き続き2連続での経済産業大臣賞の授業となりました。まさか二次予選最下位からこのような賞を受賞できるとは思ってもいませんでした。本当にチームメンバーに感謝です。
おわりに
あれ?今後参加したい人や興味を持ってくれるであろう人に向けて大まかな流れを書いたつもりが、なんかふわふわしたものしか書けていない気が…
まずは、参加してくれた「sawayaka-sec A」および「sawayaka-sec B」チームメンバーの皆様、本当にありがとうございます。そして、コンテスト中に至らぬ点やご迷惑をかけたことがあったと思います。本当に申し訳ありませんでした。
また、このような状況にも関わらず、決勝戦までオンラインで開催した第15回情報危機管理コンテストの運営の皆様に感謝申し上げます。3月頃からイベントが軒並み中止になっていた状況を見ていて、「今年はないんじゃないか…」と不安だったので、参加できて本当にうれしかったです。更に、今年はライブ中継もあったので、後で見直して二度楽しむことが出来ました。ただ、やはり白浜にいけなかったことだけは残念でした…
コンテスト全体の話に移りますが、毎年非常に凝ったシナリオに沿った問題が出題されるので、今年も新鮮で楽しい時間をすごすことが出来ました。一次予選では学生が経験しないようなコンサル関係の問題、二次予選と決勝では現実的な内容に沿った実践的な問題と、一つのコンテストで様々な問題経験が出来て、本当に楽しかったです。特に、問題環境で使用するようなネットワークやサーバ構成は、普段の生活では触らないようなものばかりなので、色々と勉強になりました。
個人的な感想として、二次予選で最下位といわれていた状態から、まさか経済産業大臣賞を受賞することになるとは思ってもいませんでした。また、弊学として参加を開始した2年前から大学単位で考えると、
と言った感じなので、本当に驚いています。学習目的という観点からも、今年はチーム内で全員学年が異なっていて、かつ経験者が最低1人以上いるチームになったので、非常に良い構成になったと思います。
私は次回から参加することは出来ませんが、コンテストを通じて、少しでも弊学にセキュリティに興味を持ってくれた人が増えたのであれば幸いです。3年間、本当にありがとうございました!
後日談
8月頃に、チーム対するコメント(講評のようなもの)を運営の方よりいただきました。コメントを読んだ感じだと、チーム内の雰囲気(ワークフローやコミュニケーション)が良かったようです。また、飛び抜けた部分はないものの、最終的に評価をつけたところ経済産業大臣賞を受賞することになったとのことでした。実際の現場がどのようなものかわかりませんが、個人的にはトラブル対応が発生した場合においても冷静に安定した業務を遂行することが重要だと思っているので、「飛び抜けた部分がない」というのはいい意味で良かったのかな、と思っています。
また、情報危機管理コンテストの開催元(?)である「サイバー犯罪に関する白浜シンポジウム」の講演を聴講することができました。こちらも詳細な内容は言わない方が良いと思うので控えますが、普段だと情報機器管理コンテスト参加者はシンポジウムの講演を聴講することができない(というか聴講する暇がない)ので、面白い話を聞くことができて良かったです。よくやった567…(許すとはいってない)
SecHack365 2019参加記
はじめに
色々と辛いことがあって1年以上ブログを投稿していませんでしたが、2019年度のSechack365の表現駆動コースに参加しました。後々話していくのですが、私は最終的に以下の2つの成果物に参加していました。
- クエッーション ~ 位置情報 x 質問 ~
- ぼったくりガード 〜ぼったくり被害を防ぐためのシステム〜
2019年度の成果物は下のリンクにあるので、よろしければご覧ください。
参加してみて、色々と思ったこと・後悔していることがあるので、それもまとめて書いてみようと思います。この記事が公開される頃には、既に2020年度の応募の最中ではありますが、応募しようとしている人、どのコースに参加しようかなどを考えている人は、よろしければご一読ください。
なお、SecHack365に関する詳しい説明などは公式サイトをご覧ください。リンクを下に貼っておきます。
注意点
- 全てメモや写真を頼りにこのブログを書いているので、色々とうろ覚えの箇所があるとは思いますがご了承ください。
- 正直どこまで書いていいのかわからないので、簡単な内容は書きますが、実際に行ったことの詳細は書かないようにしています。
- 参加を悩んでいる状態でこの記事を読んでいる方は、「参加を悩んでいる方へ」を読むことをお勧めします。それ以外の方は、「参加を悩んでいる方へ」を読み飛ばしてもらって構いません。
参加を悩んでいる方へ
SecHack365 2020では、どうやら昨年と同様に5つのコースがあります。詳しくは、以下のリンクをご確認ください。
リンク先を見る限り、各コースによって様々な特色があると思いますが、コースを選択する際は十分に考えた上で選択するようにしましょう。「何当たり前のことを言ってるんだ」と思われるかもしれませんが、私はコース選択を誤って、応募時点でやりたかったことを何一つできないままSecHack365 2019が終了しました。そもそも1人で開発しようと思っていたにも関わらず、コース概要をよく読まずに(詳しくは「応募」に書きますが)表現駆動コースを選択してしまいました。
ただ、コース選択を誤ったからといって全く楽しくなかったわけではありません。結局複数人で開発を行いましたが、私は普段1人でしか開発を行ってこなかったので、複数人で開発するという経験はかなり新鮮なものでした。また、SecHack365自体に関しても、様々なアイデア・課題を元にものづくりを取り組んでいて、多くの刺激をもらえる場所だと思います。
長くなりましたが、結局言いたいこととしては、
- 「とりあえず応募してみよう」はやめた方がいい。
- 応募するならちゃんと考えた上でコースを選択した方が良い。
- もしコースを誤ったら、誤ったなりに楽しめるよう努力する。
くらいでしょうか。ちなみに、「興味あるならとりあえず応募しよう!」とよく言われるかもしれませんが、SecHack365において、個人的にそれはオススメできません。私みたいに、「コース選択ミスって最初にやりたいこと何1つできなかった」となっても良いならとりあえず応募しても良いとは思いますが…
1年の主な流れ
1年間何をやってきたか、各イベントごとに振り返ろうと思います。
応募
元々2018年度にも応募していたのですが、落ちてしまったので、改めて応募しました。この時、コース概要のような専用のページはなく、本当に一言説明みたいなものが開催概要ページにあり、詳しい概要は応募後に送られてくる課題フォームにありました。
とりあえず概要を見て、2018年度は3コースだったのに対して、2019年度は5コースになっていました。それで改めてコースを選びなおしていたのですが、修了生の方やトレーナーの方、指導教員などから意見を聞き、数日間考え抜いた結果、開発駆動コースに行こうと考えました。そして課題フォームに個人情報を書いてから愕然としました。私のやりたかった分野にマッチするトレーナーが開発駆動コースにはいませんでした。(2020年度のコース概要の開発駆動コースに書いてあるような内容が、2019年度は課題フォームの個人情報入力後にありました。個人情報を書かないと読めない場所に書くの本当にやめてほしいです)
某ハック、課題送信フォームを進んだ先に詳しい内容を書いてくるのやめて欲しい…
— フー (@who3411) 2019年4月18日
せっかく悩みに悩んだ結果「このコースにしよう!」と決めて進んで行ったのに、思ってたコースと全然違うものだった…悲しい…
多分この時点で応募締め切りまで残り1〜2日だったと思います。結局焦って、2018年度のSecHack365のイメージを持ったまま表現駆動コースに応募しました。(記憶通りであれば2018年度は個人での開発も行えたはず…)神奈川回後で指摘されたのですが、この時課題フォームに書かれていたらしい「グループワークで行う」という記載を完全に見逃していました。
応募で言えることとしては、
- 過去に応募したことのある人は、再度コース概要を見返した方が良い。
- 今年はコース概要ページがあるので良いが、本当にコース概要はちゃんと見た方が良い。
と言った感じです。ほんと1年前の自分に言えることなら言ってやりたいです…。
結局、なんだかんだあった応募ですが、結局合格して参加することとなりました。
表現駆動コース受かりました!
— フー (@who3411) 2019年5月2日
対戦よろしくお願いします#sechack365
神奈川回(5/17〜5/19)
合格してしばらくしてオンライン上で今後に関する話などもあり、神奈川へ向かいました。ちなみに、表現駆動コースでは前もってオンライン上で集まってグループワークがありました。グループワークの内容としては、複数のテーマから1つを選択して、それに対する課題と、解決するためのサービス・システムを提案するというものです。オンライン上で集まってグループワークを行うのは初めてで、またこれまで使用したことのないツールを使用したので、色々と新鮮だった記憶があります。
今までオンライン上でしか認知してなかった人たちを現地で見ると、「ようやく始まったなぁ」なんてことを思ってました。結局3日間は、主に以下のようなことをやったと思います。
多分アイデアソンなどは他の方が書かれていると思うので、コースワークについて書きます。アイデアソンに関して言えることがあるとすれば、あまり知識のない状態でグループの方と話をしてしまった申し訳ない気持ちになったくらいです。コースワークでは、予めオンライン上でグループワークを行った内容を発表するものでした。課題や解決策がチームによって違っていましたが、「あーそういう考え方もあるんだなぁ」と思いながら聞いていました。
あと記憶に残っていることとしては、神奈川回に表現駆動コース内で、「最終的に3人以上のグループで開発を行うこと」と言われたことですね。この時に私は絶望したと同時に、SecHackに対するモチベがマイナスくらいまで下がったことを鮮明に覚えています。今思えば、このせいで北海道回以降に多数の方へご迷惑をおかけしたと思います。本当に申し訳ありませんでした。
まとめとしては、以下のような感じです。
- SecHack365始まったな感じがした。
- 初めてのコースワークなどはそれなりに楽しめた。
- 楽しんだ後、表現駆動コースを選択したことに対して(勝手に)絶望した。
北海道回(6/28〜6/30)

そんなこんなで完全にモチベをなくした状態になったまま北海道回へ。北海道回では、グループをシャッフルした状態で、もう一度神奈川回までと同じようなグループワークを行いました。流石にグループの方々に迷惑だと思いモチベをある程度取り戻してはいたのですが、この時のグループの皆様には本当に多大なご迷惑をおかけしたと思います。
グループワークでもかなり無理くりな課題を設定してしまい、更にはその解決策も滅茶苦茶になってしまいました。今となっては本当に反省しています。この経験から、福岡回以降はかなりアイデア出しなどに関して消極的になりましたが、今思えばそれはそれで反省しています。
北海道回の3日間は、主に以下のようなことをやったと思います。
- 1日目: さくらインターネットデータセンターの見学
- 2日目: オリエンテーションやコースワーク
- 3日目: コースワーク
1日目のデータセンター見学はかなり記憶に残っています。データセンターのメモを見返してみたら、メモ欄が全て埋まっていて、更に残りの白い部分もかなり埋まっていました。詳しくは書かない方が良さそうなので省略しますが、とにかくすごかったです。
あと、2日目にワークショップが開かれたと思います。ワークショップではトレーナーの方々が用意した内容から、自分の受けたい内容を選択するものでした。私はネットワークや低レイヤーが好きなのでその関連を1つと、未だになれないプロジェクト開発関連のものを1つ選択しました。どちらもかなり面白かったと思います。
コースワークですが、基本的には神奈川回と同じことを違うグループで行うというものでした。ただ、その時に発表方法を意識したり、ポスターを用意したりと神奈川回とは違うこともいくつかありました。2分という短い時間で課題や解決策に関する発表を行うのはかなり難しかった記憶があります。
まとめとしては、以下のような感じです。
- コースワークですごい反省した。
- データセンターの見学楽しかった。
- コースワークは神奈川回と同じ内容を違うグループで行った。
福岡回(8/21〜8/23)

福岡回でも、オンラインではこれまでと同様、グループを変更して新しく課題/解決を考えました。ここまでくると、思っていたより新しい課題を見つけるのが大変だった記憶があります。あと、福岡回は中間発表があるので、他コースではこれまでの進捗を元に色々と準備されていたようですが、表現駆動コースは北海道回後から福岡回までの内容だけで中間発表を行いました。
ただ、表現駆動コースでは、福岡回からは3人以上のグループを自分たちで作って、そグループを元に成果発表まで開発を行っていくことになります。なので、それぞれがどのような課題を元にグループを作るのか、そもそも仲間外れになったらどうしようか、みたいな話が流れてたりしました。
福岡回の3日間は、主に以下のようなことをやったと思います。
- 1日目: 株式会社ヌーラボの見学
- 2日目: 中間発表
- 3日目: コースワーク
1日目のヌーラボさんの見学は、失礼を承知で言ってしまうと実はあまり記憶に残っていません。というか、正確にはヌーラボさん自身ではなく、発表内容の方が記憶に残っています。話の中では、運用中に受けたという攻撃の話もあって、個人的には特にそこが新鮮でした。演習でそのようなことはやったのですが、やはり運用中に実際に受けたという攻撃の話は面白いです。
2日目の中間発表は、ようやく他のコースの人たちが何をやっているのかがわかるようになるので、非常に面白かったです。(この辺りにならないと他のコースの人たちが何やってるかがわからないのは正直どうかと思いますが…)5コースの内容を聞いていて、個人的には学習駆動コースや開発駆動コースに憧れを持ちました。低レイヤーの話とか出てくると面白く感じてしまう奴です。あと、改めてコース選択ミスったなぁと思いました。
コースワークでは、成果発表まで課題に取り組むためのグループ作りがありました。おそらく、この時点で一度グループが決まったら、少し移動はあるかもしれませんが、基本的にはそのまま最終発表まで行く形になると思います。今思えば、何が何でもこの時点で自分のやりたいことを元にグループを集めるべきでした。が、結局コース内に同じ課題に興味を持ちそうな人がおらず(実際誰も興味を示しませんでした。多分今その話をしても覚えてない人のが多いと思います。)、色々とあってクエッーションとぼったくりガードに参加することになりました。つまり、私のやりたいことは一切できないことが確定した瞬間でもあります。
まとめとしては、以下のような感じです。
- ヌーラボさんの発表が興味深かった。
- 中間発表で5コースの話を聞けて面白かった。
- 成果発表まで2つのグループで取り組むことになった。
宮城回(10/4〜10/6)

2つのグループで取り組むことになったわけですが、宮城回時点ではそこまで忙しくありませんでした。というのも、ぼったくりガードはすでに課題や解決策がほぼ決まっていて、あとはそれに沿ってサービスを作成するのが主な作業になったからです。そんなわけで、私はクエッーションの方に積極的に参加していました。
この時点では、まだ何をやりたいかも明確に決まっておらず、ぼんやりと「地方と教育とITを掛け合わせた何かをやりたい」といった感じでした。それがいつの間にか色々と変化していき、最終的には位置情報と質問をベースにしたシステムを作りたいと考えるようになっていきました。気づいたらグループの方がクエッーションという名前とロゴを作ってくださり、なんだかんだやる気になって来たところで宮城回に入ったと記憶しています。
宮城回の3日間は、主に以下のようなことをやったと思います。
- 1日目: オリエンテーションとコースワーク
- 2日目: ポスター発表
- 3日目: コースワーク
この辺りまで来ると、コースワークや発表が中心になって来て、他の方の発表をみては焦る状態だったと思います。焦る原因は明らかに自分たちの進捗が遅れているからなのですが、自分たちは福岡回から、他コースの方は神奈川回から、それぞれ続けているから仕方ないかなぁなんて楽観視してました。(もちろん他コースの方も色々と苦戦しているのだと思っていたのですが、楽観視でもしないと焦りにやられてしまいそうだったので…)
宮城回時点では、私の参加していた2つのグループはそれぞれ以下のような状態でした。
- ぼったくりガード: 簡単なPoCもできていて、少なくとも見た目は見せられる状態
- クエッーション: アイデアだけできていて、まだイメージを図にしていただけの状態
クエッーションが明らかに恐ろしい状態であることがわかると思います。「正直これ最終発表までにシステムが完成するのか…?」と思っていました。また、このタイミングでクエッーションのアイデアに関して、トレーナーの方にアイデア出しを手伝ってもらっていたのですが、それでアイデアが発散してしまいました。それで、また一からアイデア出しを行う状態に戻ったのですが、それもあってさらに焦っていました。今思えば、当時はアイデアがうまく形になっていなかったから発散して当然か…と感じています。
あと、これは(悪い意味で)一番印象に残っているのですが、宮城回ではNight Challengeなるものがありました。表現駆動コースを2つのグループに分けて、それぞれで1つの制作物を宮城回中に作成する、というものです。結果、表現駆動コースのほぼ全員がホテルのロビーで徹夜する羽目になったのですが、なぜこのようなイベントがあるのか、今になっても理解できません。あれのせいで私は家に帰ってから体調崩して1週間以上寝込んでました。あれだけは本当に許さない。
生まれて初めて宿泊先のオフトゥンを一度も触らないまま夜が明けてしまった#SecHack365
— フー (@who3411) 2019年10月5日
まとめとしては、以下のような感じです。
- 他コースの人の発表をみて焦る。
- オフラインでも発表が増えて来て焦る。
- 思っていたよりもクエッーションが遅れていることを知る。
愛媛回(11/29〜12/1)

宮城回でただでさえ他トレーニーよりも遅れている状態で、さらにアイデアが発散してしまった状態で、この時期から沖縄回までは焦りに焦っていたと記憶しています。グループ内でも流石にやばいのではないかとなり、この頃からは1週間に2回集まってアイデアを固めていたと思います。なんか表現するというか思索してる気がする…
愛媛回では、スライドとポスターの両方を提出する必要があり、これらを提出するためにはアイデアが固まりきっていないのでアイデア出しを多く行っていたのですが、なんだかんだまとめて行けたと思います。(締切駆動開発になっていることは今更です…)あと私事ですが、この時期は学会に参加していた時期なので、あまりSechack365側に参加できていませんでした。申し訳ありません。
愛媛回の3日間は、主に以下のようなことをやったと思います。
- 1日目: デモ+ポスター発表
- 2日目: スライド発表
- 3日目: コースワーク
1日目と2日目に発表があることから分かる通り、もう愛媛回まで来ると、本来であれば自身の制作物をまとめる状態に来ています。(実際、愛媛回は沖縄回での発表練習と言われます。)そのような状態で、私の参加しているグループは、
- ぼったくりガード: 宮城回で指摘された内容を治して、かついくつか機能を追加した状態
- クエッーション: アイデアが完全にはまとまっておらず、簡単なPoCだけできている状態
といった感じでした。どうみてもクエッーションやばいですね…。とはいえ、宮城回ではアイデアをかなりボコボコにされていたのですが、愛媛回ではあまり色々と言われなかったので、アイデアがまとまって来たのかなぁと感じました。(優しくされただけの可能性もありますが…)
あと、主な内容には書いていないのですが、個人的には2日目の夜にあった落語がすごく面白かったです。普通の落語とは違い、PCなどを使っていたのですが、かなり新鮮でした。多分愛媛回で一番楽しかった時間だと思います。
まとめとしては、以下のような感じです。
- クエッーションやばい。
- 2日間の発表で、いよいよ成果発表が近づいていることを感じ始める。
- 落語楽しかった。
沖縄回(1/31〜2/2)

ここまで来ると、多分普通は成果発表に向けての最終調整とかスライドの手直しだと思うのですが、相変わらずクエッーションは大変なことになってました。また、この時にぼったくりガードの方も少し慌ただしくなってきて、両方を並行して行うので大変だった記憶があります。
クエッーションは、最終的に今思い描いている実装を成果発表までに全て行うのが難しいという判断となり、とりあえずコンセプトが伝わる範囲での作成をしました。また、これまでうやむやにしていた部分の内容も詳しく考え直し、実装とスライド作りに追われていました。
ぼったくりガードは、実装する内容が増えたので、基本的にはそれに対応できるように機能を追加・修正していたと思います。ただ、作品紹介ページを見てもらえば分かると思いますが、ぼったくりガードは8人グループだったこともあり、途中から私のやった内容がどのようにグループ内の実装に影響を与えていたのかがわかっていないという状況にありました。
そんなこんなで色々と大変だった沖縄回前でしたが、沖縄回の3日間は、主に以下のようなことをやったと思います。
- 1日目: 成果発表
- 2日目: 成果発表
- 3日目: オリエンテーションとレクリエーション
沖縄回では2日連続で成果発表がありました。中間発表では1作品5分だったのですが、成果発表では1作品20分も時間があって、自作品についてはじっくりと話すことができ、他作品についてはかなりじっくりと話を聞くことができました。作品によって見せ方や発表方法に工夫があるように見えて、正直かなり面白かったし刺激になりました。多分正確なイメージではないのですが、個人的にはかなりふんわりとした学会みたいなイメージを持ちました。
成果発表後の3日目には、レクリエーションとして斎場御嶽(せーふぁーうたき)に行きました。ここでようやく沖縄にいるような暑さを感じることができたました。(成果発表中の施設は、沖縄とは思えないくらい涼しかったです)一通り回って、かなりリフレッシュになったと思います。
まとめとしては、以下のような感じです。
- 2日間かけて成果発表を話したり聞いたりした。
- どの作品も様々な方面で工夫が見られて面白かった。
- 成果発表を聞くだけでもかなり刺激になった。
成果発表会
本当は沖縄回の後に一般公開用の成果発表会もあったのですが、残念ながら開催延期になってしまいました。こんなご時世なので仕方ないですね…。ちなみに作品一覧のポスターは成果発表会に向けて作成したもので、結局見せることのないままSecHack365 2019としての事業は終了した感じです。
SecHack365を終えて(?)

成果発表会も延期となってしまい、なんだか終了したという実感の湧かないまま時間が過ぎていますが、私にとってSecHack365が終わったかというと、あまりそういうイメージもありません。というのも、いまだにクエッーションは制作を続けています。期間中は1週間に2回ほど行っていたオンラインでのミーティングは1週間に1回となり、クエッーションメンバー全員何かと忙しいので、かなりゆっくりですが…。
まだまだ延期になった成果発表会もあるので、これからもゆっくりと時間の許す限りは作り続けて行きたいと思います。
あといくつかリアルやtwitterなどを経由して質問されたことがあるので、この場で答えておきます。
旅行楽しい?
そもそも旅行感全くないです。確かにいろんな場所に行っている感じはありますが、別に行ったからといって観光できるわけでもないです。強いて言えばご当地名物食べてお土産が買えるくらいでしょうか。旅行目的で応募しようと思ってるなら応募しない方が良いと思います。
どのコースがお勧め?
人によるのでなんとも言えませんが、とりあえずチーム開発したくないなら表現駆動コース以外で、チーム開発をしたいなら表現駆動コースです。
セキュリティ強くなった?
正直応募前とほとんど変わらないと思います。元々セキュリティ系の研究室なのと、情報処理安全確保支援士試験を合格しているので、知識だけはあると思います。(実装力はないので詳しい話になるとさっぱりですが…)ただ明確に変わった部分として、法律面はそれなりに変わったと思います。詳しくは言えませんが、法律に関するセキュリティのお話もSecHack365内でありました。
技術力ないとダメ?
これはコースによると思いますが、チーム開発であればマネージャーのような役割をこなすことができるのではないでしょうか。また、研究駆動コースのような方面であれば、実装よりも仮説検証などがメインになると思う(研究駆動コースを受けてないのでこれはかなり適当な考えです)ので、絶対にこれだけ技術力がないとダメ!みたいなものはないと思います。結局、必要になればやらざるを得ないので、人に意見を聞きながらでも学習できるような意欲があればいいのではないかと思います。
おわりに
すごいざっくりと、そしてだらだらと1年間を振り返って見ましたが、やはり後悔が大きいですね。特にコースの選択を間違えたことはいまだに後悔していて、できることなら去年からコースを選択し直してやり直してみたいくらいです。とはいえ、表現駆動コースが悪かったというわけではなくて、表現駆動コースだったからこそ、そもそもやろうと思っていなかった複数人の開発ができたという面はあるので、そういう意味では貴重な時間を過ごすことができたと思います。単に私と表現駆動コースの相性が悪かっただけだと思ってます。
1年間という長い時間を学業や仕事と並行して行う必要があるので、もちろん大変ではあるのですが、やりたいことがあって、なおかつSecHack365に興味があれば応募してみると良いと思います。ただ、コース選択はくれぐれもお気をつけください…。
これまで調べてきたファジングの話
この記事は静大情報LT大会(IT) Advent Calendar 2018の21日目の記事になります。
はじめに
今年度は、静大情報LTで情報危機管理コンテストやボゴソートの話をしていたものです。
最近はまともなアウトプットを一切行っていなかったので、この機会にファジングに関する話をしようと思います。また折角ブログとして投稿するので、5分では語りきれないような内容について書こうと思います。
ちなみに、この記事にプログラムはほとんど出てきません。プログラムを読みたい、という方がいらっしゃいましたら、先日ブログに書いた、こちらの記事を読むことをお勧めします。
注意
注意深く調べてはいますが、この記事の情報が必ずしも全て正しいわけではありません。予めご了承した上で読んでいただければと思います。
ファジング
ファジングとは、プログラムに対して自動的に生成した大量のデータを送ることで、データを送ったプログラム側の応答や挙動を確認する、脆弱性診断やテスト手法の1つです。また、ファジングを行うためのソフトウェアやツールのことを、ファザーと言います。ファザーには、American Fuzzy LopやlibFuzzerなどがあり、多くの脆弱性が発見されたりしています。
近年の出来事だと、あらかじめ用意されたプログラムの脆弱性を発見・パッチ記述・攻撃コード作成といった流れを自動化するコンテストであるDARPA Cyber Grand Challengeにおいて、決勝まで進出したDrillerやAFLFastなどがファジングを使用しています。またファジングと機械学習を組み合わせることで、ファジングの性能をあげる研究も行われています。
このようなファジングに関して、今回は歴史や動向を話すことができたらと思います。
ファジングの歴史
1990年にMillerらによって発表された論文時点では、大量に生成したデータを用いて、クラッシュやハングを検出するのみでした。大量のデータを生成するプログラムと、対話型プログラム用に記事デバイスファイルを作成するプログラムを使用することで、様々なプログラムに対してファジングを実施するというものでした。1995年の論文では、GUIベースのツールや、ネットワーク、システムライブラリなどに対してファジングをかけた結果が記載されました。
1998年、フィンランドのオウル大学でPROTOSプロジェクトが行われました。このプロジェクトでは、プロトコルの脆弱性に関するファジングを行うもので、多くの脆弱性を発見することに成功しました。PROTOSプロジェクトは、2002年にCodenomiconという商用のファジングに関する会社の設立まで行く様になりました。Codenomicon社は、OpenSSLに含まれていた脆弱性であるHeartbleedを検出するなど、多くの活躍をしています。
Codenomicon社が設立された2002年、Dave AitelがSPIKEという、オープンソースでプロトコルのファジングを行うことができるツールを開発・公表しました。SPIKEでは、ブロックサイズ情報を記録しておくことで、多くのヘッダがネストされるネットワークのようなシステムに対しても、ファジングを行うことができる様になっています。またDave Aitelは、sharefuzzという環境変数に対するファジングも公表しました。初期にはプログラムの入力のみ対象にしていたファジングが、ネットワークやプロトコル、環境変数など、だんだん範囲が広がって行く様になりました。
その後、ファイルやブラウザなど、だんだんと対象とする範囲が広がっていきながら、多くのファジングが登場する様になっていきます。
ファジングの分類
ファジングでは、主に3つの視点での分類が存在します。
- 入力をどの様に生成するか
- プログラムに入力する際の構造を認識しているか
- プログラム自体の構造を認識しているか
以降、それぞれの視点での説明を行っていきます。
入力の生成方法
入力の生成方法では、主に以下の2つが存在します。
- 突然変異ベース: 入力の元となるようなデータであるシードを突然変異させて行くことで、その突然変異したものを入力データとして利用する方法(ex: シード"hello" →突然変異→ "hellm")。この方法の場合、シードの中身にあるデータによって、脆弱性の発見率が左右する場合があります。
- 生成ベース: 何も情報がない状態か、入力のモデル(最初の2バイトは数字、続く4バイトは文字列…といった情報が続いたもの)がある状態から入力データを生成する方法。この方法の場合、突然変異ベースのシードを必要としないので、脆弱性の発見率を左右するようなものはありません。
また場合によっては、突然変異ベースと生成ベースを組み合わせた手法も存在します。
プログラムに入力する構造の認識
プログラムに入力する構造の認識の有無によって、以下の2つに分かれます。
- smart fuzzer(スマートファザー): 入力のモデル(最初の2バイトは数字、続く4バイトは文字列…といった情報が続いたもの)を使用しながらファジングを行う手法。ヘッダが多く使用されるネットワークプロトコルなどに対しては有効な手法ですが、プログラムごとに入力モデルを用意する必要があり、コストがかかります。
- dumb fuzzer(ダムファザー?): 入力モデルを使用せずにファジングを行う手法。入力モデルがない分、有効となる入力を生成できる可能性は低くなりますが、汎用的にファジングを行うことができます。
プログラム自体の構造の認識
プログラム自体の構造の認識では、主に以下の3つが存在します。
- ホワイトボックス: プログラムの内部構造を知っている状態で行うファジング。到達しにくい場所にある脆弱性を発見することもできますが、プログラムの分析自体に時間がかかる可能性が高いです。
- グレーボックス: プログラムの内部構造は不明だが、プログラムの動作などを監視して情報を収集しながら行うファジング。ホワイトボックスと違って内部構造はわかりませんが、プログラムの動作を介して、ある程度プログラムにあった入力を生成することができます。
- ブラックボックス: プログラムの内部構造を全く知らない状態で行うファジング。グレーボックスと違って情報収集も行わないので、完全にランダムな入力データの生成を行いますが、並列化や高速化が可能です。
様々なファジング
近年、様々なファジングが提案・発表されています。ここでは、その一部について見ていこうと思います。
オープンソース・製品
オープンソースや製品化されているファザーは多く存在しますが、4つのファザーについて話したいと思います。
Taof
Windows上で動作する、HTTPサーバやFTPサーバといったネットワークを介するファジングを行います。クライアントとサーバの間に立ってデータ収集を行うことで、情報を収集します。
Peach
ソフトウェア全般に対してファジングを行うことができます。XMLファイルを用いて、ファジングの対象となる値の形式などを決めることで入力モデルを作成し、そのモデルに沿った値を生成していきます。こうすることで、ヘッダのような、予め形式の決まっているプログラムに対してのファジングを行うことが可能となっています。
AFL(American Fuzzy Lop)
ファジングを行うプログラムのコンパイル時に計測用のコードを埋め込み、ファジングの実行時には、埋め込んだ計測用コードによって情報を収集します。計測用コードでは、「どの計測用コードからどの計測用コードへ移動したか」を見ることで、新しい遷移があったかを検出します。(ex: これまではA→Bの遷移しかなかったが、新しく生成した入力ではA→Cへ遷移した)
AFLの簡単な動作説明は以下の通りです。
- シードとなる値を複数用意し、その中から1つ選択する。
- 選択したシードを突然変異させ、プログラムへの入力する。
- プログラム実行後、新しい場所へ遷移した入力などがあれば、その入力をシードに追加する。
libFuzzer
libFuzzerは、AFLと同様、遷移に関する情報を利用したカバレッジベースのファジングを行います。またAFLとの互換性もあり、例えばAFLである程度プログラムに対してファジングを行った後で、libFuzzerで同じプログラムのファジングを途中から行うことができます。
libFuzzerでは、通常のファジングだけでなく、特定の関数のみを対象としたファジングを行うことができます。この手法はメモリ内ファジング(In Memory Fuzzing)と呼ばれており、特定の関数をテストするには持ってつけの機能と言えます。
AFLの派生
AFLでは、AFLを利用した多くのファザーが存在します。ここでは、そのようなファザーについて話していきます。
ちなみに、AFLはC言語で記述されているのですが、様々な言語で使えるようになっているようです。例えば、KelinciはAFLをJavaで使えるようにしたもので、afl.rsはAFLをRustで使える様にしたものです。
AFLFast
AFLでは、1つのシードを選択すると、そのシードを元に突然変異を複数回実行します。またシードはキュー(FIFO)の構造になっているため、後ろの方に脆弱性を発見しやすいようなシードがあったとしても、選ばれるのはかなり先のことになってしまいます。
AFLFastでは、まずシードを選択してから突然変異を実行する回数を調整するようにしました。基本的にはAFLよりも突然変異回数を少なくなるにしており、6種類の実行回数の計算式が存在します。またシードの選択方法は、他のシードが遷移していない場所に遷移しているパスや、選択回数の少ないシードを優先的に選択するようにしました。
結果として、AFLFastは前期のDARPA CGCで決勝まで進出していることからも、この方法は有効だったと言えます。
AFLGo
AFLGoでは、現在地にとなる場所と目的地となる場所の距離を求めることで、目的地まで到達することを目標としたものです。関数の呼び出し関係を表すコールグラフや、プログラムの全経路をグラフ化した制御フローグラフなどを用いることで、距離の計算を行います。
aflpin
aflpinは、計測用コードを埋め込んでいない実行ファイルに対して、Intel Pinを利用することでAFLの様にファジングを実行しようというものです。ですが、近年ではaflpinがうまく動かないことが増えてきて、代わりにafl-pinを使用する必要が出てきました。
CollAFL
CollAFLは、AFLで収集する情報をより正確に提供し、シード選択時ポリシーを改良したファザーです。実は、AFLでは、対象となるプログラムによっては100%正確な遷移情報を収集することができません。この問題は、情報収集時にハッシュ衝突が発生するからです。
それに対して、CollAFLでは、貪欲法を用いることで、全てのハッシュが衝突しないようにしておきます。またシード選択については、AFLのキュー形式ではなく、メモリアクセス操作が多い入力などを優先して選択する様にしています。
他解析手法との組み合わせ
シンボリック実行やテイント解析など、他の解析手法と組み合わせたファザーが存在します。ここでは、それらを紹介していきます。なおシンボリック実行とテイント解析については、以下の通りです。
- シンボリック実行: プログラムの変数や入力を一つのシンボルとして扱うことで、実行パスの制約を維持する手法です。シンボリック実行やコンコリック実行については、このスライドが凄く分かりやすかったです。なおコンコリック実行は、シンボリック実行で求めた制約を元に、実際に値を生成・入力する手法です。
- 下の図のように、プログラムをパスとして考えてみましょう。右図の緑の部分にいきたいとします。その時、それぞれの緑の部分に行くために必要となる論理式は緑の部分に記述されています。この論理式通りの値を出力することができたら、全ての箇所に遷移することができます。
- 注意点として、シンボリック実行やコンコリック実行では、時間がかかることはもちろん、条件式が多すぎるとパスが多くなりすぎるという問題もあります。

- テイント解析: パケットやファイル、標準入力といった外部から入力される値が格納されているメモリ番地を、「汚染された」状態とみなして、その伝搬を追跡する手法です。
- 「汚染された」データと「汚染されていない」データを計算した時、計算結果も「汚染された」データとなっていきます。
- 「汚染された」データ周りの命令が脆弱性に繋がりそうか確認すれば、入力データ周りの情報収集を行うことができます。
Driller
Drillerは、ファジングとコンコリック実行を交互に行うことで、深い位置にある脆弱性を発見するためのファザーです。具体的な手順は以下の通りになっています。
- テストケースを入力
- ファジングを実施し、新たな遷移が不可能となった時に手順3へ
- 不可能となった区間に対してコンコリック実行を実施
- 手順3の実行結果から得られた値をファジングの入力へ
- 手順2から手順4を繰り返す
BuzzFuzz
BuzzFuzzは、動的テイント解析を使用したファザーです。初期準備として、シードの値を入力としてプログラムを実行し、その際に動的テイント解析を利用することで、影響を与える入力バイトを記録します。そして、この時に得た入力バイトの位置を記憶しておくことで、ファジングによって変化させる値の位置を決定します。
VUzzer
VUzzerは、静的解析と動的解析を行うことで、効率的に入力データを生成するファザーです。具体的な手順は以下の通りです。
- 実行ファイルを静的解析する。
- アセンブリの"cmp"命令や"lea"命令に当たる部分を調査する。
- これまで得た情報を元に入力を生成し、実行ファイルを実行する。
- 手順2の実行時に得られた情報を元に、次に実施する変異戦略などを求めるための計算を行う。
- 手順2に戻る
Munch
Munchは、ファジングとシンボリック実行を組み合わせたファザーです。ファジング→シンボリック実行の順に実行するFSモードと、シンボリック実行→ファジングの順に実行するSFモードの2つが存在します。
fFuzz
fFuzzは、ファジングとシンボリック実行を組み合わせたファザーです。fFuzzでは、以下の2つの最適化手法を用いることで、脆弱性の発見を最適化します。
- 冗長なテストケースの破棄
- パス爆発の発生を抑える選択的シンボリック実行エンジン
QSYM
QSYMは、ファジングと組み合わせることを前提として、コンコリック実行のパフォーマンスのボトルネックとなる部分を分析し、ファジングのサポートに適したコンコリック実行の作成を行っています。具体的には、命令レベルでシンボリック実行を行ったり、繰り返し実行しているブロックを検出して、その部分をコンコリック実行の対象から取り除いたりします。
その他の手法
ファジングでは、上であげた以外にも、様々な種類が存在します。ここでは、その他の手法を記載していきます。
kAFL
kAFLは、カーネルのファジングを可能としたファザーです(AFLの派生なのですが、カーネル関係として記述しています)。KVM上でファジングを行う対象となるカーネルを起動させて、QEMU上でファジングを実行します。入力した動作をトレースする方法として、Intel PTを使用しています。
正しく理解するには必要となる知識が多いのですが、今回は省略しています。わからない専門用語などがある方は「カーネルもファジングできるんだ〜」くらいに思っておいてもらえば幸いです。「カーネルって何?」という人がいれば調べてみましょう。
SlowFuzz
SlowFuzzは、脆弱性といったものを見つけるのではなく、実行速度が低下するような入力を見つけ出すファジングです。実行速度を遅くするため、シードを選択する際の方法としても、実行速度の遅くなるようんあものを優先的に追加するようにしています。SlowFuzzについては、先日あげた記事(「はじめに」と同じ記事です)で、AFLとIntel Pinを組み合わせた実装を行いましたので、よろしければそちらもご覧いただけると、より理解が深まるかと思います。
SemFuzz
SemFuzzは、gitログやCVEといった脆弱性に関係した情報を収集することで、攻撃用の入力を自動的に生成するファザーです。具体的な手順は以下の通りです。
- CVEとgitログを、自然言語処理を使って分析し、影響のあるバージョン、脆弱性の種類・機能、重要な変数、システムコールなどを抽出します。
- 対象のバージョンとなる仮想マシンを起動し、ファジング環境を準備します。
- 手順1で抽出した情報を利用して、シード入力を生成してファジングを実行します。
SSFuzzer
SSFuzzerは、AFLのような遷移情報や、Vuzzerのような比較命令に焦点を当てた方法とは異なり、関数呼び出しやメモリアクセスなどといった情報を利用することでファジングを行います。情報収集の際、プログラムをデコンパイルすることで、どのような関数が呼び出されているか、などを判定します。CVEの多い関数呼び出しを行っているもの、メモリアクセスの頻度が多いものなどは点数を大きくして、エラーハンドリングが行われているものは点数を小さくします。
Skyfire
Skyfireは、XMLファイルのような高度な構造化が必要とされるファイルを入力とするプログラムに対して、効率的なシードを生成する手法です。ファジングそのものではないのですが、入力生成まで行っていること、最終的にSkyfireとAFLを組み合わせた実験などを行っていることなどから、この場で紹介します。この手法では、確率文脈依存文法(PCSG)と呼ばれるものに学習を行わせて、学習した内容にしたがって入力を生成します。
ここでは、PCSGに代わって、ディープラーニングといった学習アルゴリズムを適用できる可能性をあげています。実際に機械学習を用いたファジングが出てきている現状では、Skyfireは改良できるかもしれません。
IOTFUZZER
IOTFUZZERは、IoTファームウェアのメモリ破損に関する脆弱性検出に特化したファジングです。モバイルアプリケーションでのやり取りを確認することで、ファジングを行います。IOTFUZZERの具体的な手順は以下の通りです。
- IoTのモバイルアプリケーションのうち、ネットワーク送信イベントをトリガします。
- 送信しているメッセージの中から、プログラム実行に関連する値を見つけ出します。
- 実行ごとに変化している値などがあれば、その値をファジングによって変えることで脆弱性を発見できる可能性があります。
- 独自に定義したポリシーに従って手順2で見つけた値を突然変異させて、ファジングの対象とするデバイスに対して送信します。
FUZE
FUZEは、Use-After-Free(UAF)と呼ばれる脆弱性を評価するためのフレームワークで、内部的にファジングを使用しています。FUZEの実行途中において、UAFを引き起こすシステムコールを見つけ出す必要があるのですが、その時点でファジングが使用されます。
Angora
Angoraは、シンボリック実行を用いてパス制約を解決していた各手法に対して、シンボリック実行を用いずにパス制約を解決するものです。
関数呼び出しの引数を考慮(func(input[0])とfunc(input[1])を区別する)したり、条件文に使用される入力バイトを識別したりすることによって、ファジングとシンボリック実行を組み合わせる際の、シンボリック実行の代替となるようなシステムの開発を行っています。
T-Fuzz
T-Fuzzは、ファジングが調べることが難しい「str == ".PNG"」のような、いわゆるサニティチェックの条件文を取り除くことでファジングを行います。
実は、ファジングでは「str == ".PNG"」のような固定値との比較は非常に困難です。画像ファイルを処理するようなプログラムでは、画像のヘッダで使用されるマジックバイト(ファイルの先頭にある、その画像ファイルの種類を示す値)のチェック(サニティチェック)などが行われますが、ファジングはここを通るのが非常に難しいです。そこで、そのような部分は取り除いてしまおうというのが、T-Fuzzの考え方です。
ちなみにプログラムの取り除き方ですが、条件分岐を反転させることで取り除いています。
MoonShine
MoonShineは、プログラムからシステムコールのトレース結果を収集・抽出することで、プログラムにあったシードを自動的に生成する手法です。ファジングそのものではないのですが、ファジングに使用するシードは、ファジングの結果に大きく左右されるため、この場で紹介します。 MoonShineの主な手順は以下の通りです。
- トレースするプログラムを実行し、カバレッジ情報の記録やシステムコールのキャプチャを行う。
- 手順1で収集した情報からトレース結果を出力する。
- 手順2のトレース結果、および手順1のカバレッジ情報から、シードの蒸留を行います。
- 手順3で蒸留したシードをファジング実行時のシードとします。
Hawkeye
Hawkeyeは、AFLGoのような静的解析とファジングを組み合わせた手法について、望ましいと思われる特性を実現するための解決策を提案しています。
まず静的解析を用いてコールグラフと制御フローグラフを生成します。そこから、隣接する関数の距離、基本ブロック間の距離、目標位置に到達可能な関数などを計算します。
次にファジングを実施します。具体的な手順は以下の通りです。
- 静的解析で収集した情報やシードの優先順位に基づいて、突然変異するシードを選択します。
- シードの変異回数、変異戦略といったファジングを行うために必要な情報を決定したのち、突然変異を行います。
- 変異した値をプログラムの入力値として、目的のプログラムを実行します。
- 目標位置までとの距離などを計算し、シードの優先順位を決定します。
- 手順1に戻ります。
おわりに
まだまだ紹介したいものもあったのですが、残りは自分で調べてもらえると幸いです。(アドベントカレンダーの期限まで時間がなかった…)
今回は、詳しい中身を知らずとも、ある程度理解できる様に書いたつもりですが、わかりづらかったらすみません…。
ファジングは、海外では活発なイメージがあるのですが、なぜか日本ではあまり知られていないように思えます。私としては、もっと国内でファジングが流行ってくれたらなぁと思います。
12/21の本記事投稿時点で、次の記事は12/22のhi97_ia16さんによる記事です。お楽しみに!
American Fuzzy LopとIntel Pinを組み合わせたい
この記事はセキュリティキャンプ 修了生進捗 #seccamp OB/OG Advent Calendar 2018の18日目の記事になります。
はじめに
セキュリティキャンプ全国大会2017で参加させていただいたwho3411です。最近ファザーであるAmerican Fuzzy Lopに、動的解析を組み合わせようとわちゃわちゃしていました。この記事は、最終的にAmerican Fuzzy Lopと動的バイナリ計測ツールであるIntel Pinを組み合わせて遊びたいと思います。なお、American Fuzzy Lopのコードリーディング時に使用していたhackmdを公開します。American Fuzzy Lopのコードリーディングをする方の助けになればと思います。(する方がいればの話ですが…)
ファジング
American Fuzzy Lop(以下、AFLと呼ぶ)は、簡単に言うと、ファジングを行うための軽量なファザーです。この時点で、「ファジング?」「ファザー?」となると思うので説明しておくと、
- ファジング: プログラムに対して自動的に生成した大量のデータを送って、送られたプログラム側の応答や挙動を確認することで、脆弱性診断やテストを行う手法
- ファザー: ファジングを行うためのソフトウェア、またはツール
です。ファジングにはブラックボックス,グレーボックス、ホワイトボックスなど、様々な種類のファジングがありますが、AFLはグレーボックスになります。雑に説明すると、
- ブラックボックス: プログラムの中身がわからない状態
- グレーボックス: プログラムの中身はわからないけど、計測などを行って情報を収集する
- ホワイトボックス: プログラムの中身がわかっている状態
みたいな感じです。AFLは、後述しますが、ファジングをかけるプログラム側に計測用のアセンブリを入れ込んで計測を行います。
動的バイナリ計測(Dynamic Binary Instrumentation)
Intel Pinは、簡単に言うと、動的バイナリ計測(Dynamic Binary Instrumentation, DBI)を行うことができるツールです。DBIは、実行中のプログラムに対してコードを挿入する技術ですが、Intel Pinでは、プログラムの実行中だけではなく、ロード時点でもコードを挿入することができます。
Intel Pinの、プログラムの実行中にコードを挿入する方法では、命令単位、基本ブロック単位、トレース単位の3種類があり、トレース単位が最も大きい単位になっています。なので、トレース単位は複数の基本ブロック単位を含んでいる可能性があり、また基本ブロック単位は複数の命令単位を含んでいる可能性があります。
Intel Pinは、多くのマニュアルコードがあり、例えばプログラム全体で実行された命令数をカウントするプログラムや、読み書きされたメモリアドレスをファイルに出力するプログラムなどがあります。詳しくは、Intel Pinのサイトを見ることをお勧めします。
AFLとIntel Pinを組み合わせる手順
今回は、AFLがプログラム中に入れ込んでいる計測用のアセンブリだけではなく、Intel Pinで収集した情報も含めてファジングを行うようにすることをゴールとしていきます。そのために、以下のような手順で進めていこうと思います。
- AFLがファジングを実行するまでの流れを知る
- AFLとIntel Pinを組み合わせる方法を探る
- 実際に組み合わせてみる
AFLがファジングを実行するまでの流れ
AFLでは、AFL用のコンパイラであるafl-gccでコンパイルを行い、ファジング本体であるafl-fuzzでファジングを行います。afl-gccを読んで見ると、色々とコンパイルオプションをつけた上でgccでコンパイルしているようでした。その中で重要なのが -B オプションで、これはgcc内部で実行されるプログラムである cpp 、 cc1 or cc1plus 、 as 、 ld のディレクトリを指定するオプションです。このオプションで、afl-gccはカレントディレクトリを指定しています。AFLディレクトリ直下をみてみると、 as が存在しています。これは、AFL用のアセンブラであるafl-asのシンボリックリンクで、つまりafl-asを見れば良さそうです。
afl-asの計測用コードの内容
afl-asを見てみると、計測用のコードを挿入した上で、オプションをいくつかつけて本来の as を実行していました。計測用コードは、複数箇所挿入されていました。計測用コードにはいくつかの条件がありますが、基本的には j + m 以外の命令( je 、 jl などの条件分岐)の手前に挿入します。
また、計測用コードは以下のような手順になっています。(詳しく読まなくてもいいという人は、以下の箇条書き部分を飛ばしてください)
- いくつかのレジスタを保存し
__afl_maybe_logに遷移する。この時、rcxにid(乱数 % MAPSIZE)を格納しておく。なお乱数は、アセンブリコード挿入時点で確定しているため、ファジング実行ごとに変化する訳ではない。(MAPSIZEは、65536である) - AHにフラグを保存し、
__afl_global_area_ptrの値を確認し、0であれば__afl_setupに遷移する。また0でなければ__afl_storeに遷移する。__afl_storeではprev_id ^ idを行いrcxに格納した後、prev_idを__afl_prev_locに格納し1ビットシフトする。最後に、__afl_prev_locの該当する位置をインクリメントし、そのまま__afl_returnへ入る。__afl_returnでは、保存したフラグを復帰したのち、ret命令を行う
__afl_setup_failureが0でなければ、__afl_returnに遷移する。__afl_setup_failureが0であれば、__afl_global_area_ptrの値を取り出しテストを行ったのち、__afl_setup_firstに遷移する- 様々なレジスタを保存したのち、
r12にスタックポインタを保存してrspを0x10減算したのち、rspの下位4ビットを0にする。- 減算して下位4ビットを0にするのは、スタックは16bit境界であることを前提としているため
.AFL_SHM_ENVの環境変数を取得し、 結果が0であれば__afl_setup_abortへ遷移する__afl_setup_abortでは、保存したレジスタを復帰したのち、__afl_returnへ遷移する
- 結果が0でなければ、結果を
atoiで数値に変換する。 - その後、
shmatで共有メモリを作成する。この時、shmatの結果が-1であれば__afl_setup_abortへ遷移する。 shmatの結果である共有メモリアドレスを__afl_area_ptrおよび__afl_global_area_ptrに保存し、rdxへ格納しておく。そしてそのまま__afl_forkserverへ入る。- 2度
rdxをプッシュしたのち、FORKSRV_FD + 1のファイルディスクリプタに対してデータをwriteする。戻り値が4でなければ__afl_fork_resumeへ遷移する。__afl_fork_resumeでは、共有メモリのクローズ、スタック領域からレジスタへの復帰を行い、__afl_storeへ遷移する。
- 戻り値が4であった場合、そのまま
__afl_fork_wait_loopへ入る。 FORKSRV_FDのファイルディスクリプタに対してファイルをreadする。戻り値が4でなければ__afl_dieへ遷移する。__afl_dieでは、exit(0)に相当する命令が実行される。
- 4であれば、
fork()を行う。この時、戻り値が0未満であれば__afl_dieへ遷移し、0であれば__afl_fork_resumeへ遷移する。- この時、
FORKSRV_FDおよびFORKSRV_FD + 1がクローズされるため、生成された子プロセスは通常のプログラム実行へと遷移していく。(main関数の最初に__afl_maybe_logが実行されるため)
- この時、
- 次に
__afl_fork_pidへ戻り値である子プロセスIDを格納し、子プロセスIDをFORKSRV_FD + 1のファイルディスクリプタに対してwriteする。 - その後、子プロセスIDに対して
waitpidを実行し、戻り値が0以下であれば__afl_dieへ遷移する。そうでなければ、waitpidで取得したstatusを子プロセスに対してFORKSRV_FD + 1を経由してwriteする。 - 最後に
__afl_fork_wait_loopへ遷移することで、ループ処理となる。
上記の内容を簡単にまとめると、こんな感じになります。
- 最初に計測コードに入ったら、環境変数
SHM_ENV_VARから共有メモリ用の値を取得し、その値を利用して共有メモリにアタッチする。 - 後述するAFLのforkserver用の受信用ディスクリプタである
FORKSRV_FD + 1に対して、4バイトのデータをwriteする。 - 後述するAFLのforkserver用の送信用ディスクリプタである
FORKSRV_FDから4バイトのデータをreadする。 forkを行い、子プロセスは本来のプログラムを実行し、親プロセスはFORKSRV_FD + 1から子プロセスidをwriteし、waitpidによって子プロセスの終了を待つ。- 子プロセスは、今後計測用コードに入るたびに、「どの計測用コードからどの計測用コードへ遷移したのか」という情報を、ステップ1でアタッチした共有メモリに追加していく。
- 共有メモリは64KBあるため、計測用コードを識別するidは16ビットになっている。
- 遷移前の計測用コードのidを
prev_id、遷移先の計測用コードのidをcur_id、共有メモリをtrace_bitsとした時、trace_bits[(prev_id >> 1) ^ cur_id]を加算することで、遷移情報を記録している。
- 子プロセスの終了後、
FORKSRV_FD + 1からwaitpidの引数であるstatusをwriteし、ステップ3へ戻る。
一言で言ってしまえば、プログラム中の遷移情報を計測している、というだけです。あと面白いのは、fork を行い、AFL本体とやり取りを行うための親プロセスを常駐させている点です。(これのおかげで、プログラムを実行するごとに shmat などを行う必要がなくなっています)ちなみに、AFL本体では共有メモリ trace_bits の情報を使用することで、効率的にファジングを行うようにしています。
計測用コードとファジングの関係性
前記の計測用コードでは、 FORKSRV_FD と FORKSRV_FD + 1 を用いてAFL本体とのやり取りを行っていました。やり取りの際、どのようなデータを送っているか、またAFL本体ではどのような処理を行っているのかを知る必要があります。その部分を知るために、ファジングを行うafl-fuzzを見て、流れを確認しようと思います。なおafl-fuzzのコードリーディングでは、以下のサイトが非常に参考になりました。
afl-fuzzでは、forkserverと呼ばれる仕組みが用意されています。計測用コードの説明でも何度か出てきましたが、forkserverは、前記の計測用コードの親プロセスに当たります。つまり、
- afl-fuzz: forkserverとやり取りを行い、プログラムを実行してもらう。
- forkserver: afl-fuzzとやり取りを行い、
forkによってプログラムを実行する。
という感じです。forkserverの設定は、afl-fuzzの init_forkserver 関数を読むと書いてあります。 init_forkserver では、 fork を行い、子プロセスから execv によって計測用コードを埋め込んだプログラムを実行しています。最後に、forkserverから4バイトのデータを受け取ることができたら init_forkserver を終了します。
次にforkserverが出てくるのは、afl-fuzzの run_taget 関数です。 run_taget では、forkserverとやり取りをすることで、プログラムを実行してもらいます。まずafl-fuzzからforkserverに向けて、4バイトのデータを write します。次にforkserverから子プロセスidを受け取り、最後にforkserverから子プロセスの終了ステータスを受け取ります。
AFLとIntel Pinを組み合わせる方法
AFLとIntel Pinを組み合わせるには、以下のようなことをすれば良さそうです。
- ファジングの対象となるプログラムを実行するより前に、共有メモリ
trace_bitsを用意しておく。- 環境変数
SHM_ENV_VARの値を利用して、shmatによって共有メモリをアタッチする。
- 環境変数
- ファジングの対象となるプログラムの実行直前に、forkserverにあたるコードを実行する。
- 「afl-asの計測用コードの内容」でまとめたステップ2から5にあたるコードを実行する。
trace_bits[(prev_id >> 1) ^ cur_id]を加算して遷移情報を記録する部分を作成する。- 条件分岐命令の手前に
trace_bits[(prev_id >> 1) ^ cur_id]++にあたるコードを挿入する。
- 条件分岐命令の手前に
という感じに、色々と読んだ上でやり方を考えていたら、こんなリポジトリを発見しました。
どうやら、やろうと思っていたことが全部含まれているようです。このリポジトリでは、以下のような処理を行うコードが用意されています。
forkserver.cのstartForkServer関数では、forkserverに関する部分を一括して請け負っている。startForkServer関数は、ファジングの対象となるプログラムを読み込んだ時、Intel Pinでmainの最初の命令の手前にstartForkServerを実行している。- ファジングの対象となるプログラムの
main関数の最初の命令実行後、PIN_Detach()によって、解析対象プログラムから離れる - 以上の動作により、forkserverをintel PINの使用により解決している。
- ファジングの対象となるプログラムの
- ブロック遷移では、
ret命令ではなく、条件分岐命令かつ分岐先アドレスが命令ポインタからのオフセットか即値でない部分(メモリやレジスタからの値)の場合にtrace_bits[(prev_id >> 1) ^ cur_id]++にあたるコードを実行するようになっている。乱数 % MAP_SIZEであったidは、分岐先のアドレスを使用することで代用している。
これによって、AFLとIntel Pinを組み合わせたファジングを行うことができるようになりました。
新たな情報を収集したファジングを行う
何を作ろうかと考えた結果、ACM CCS 2017で発表されたSlowFuzzを、AFLとIntel Pinを組み合わせて作ることにしました。通常、ファジングは脆弱性を発見するために用いられますが、SlowFuzzでは実行時間の長くなるような入力を発見します。その際に用いられる情報は、プログラムの命令実行数です(SlowFuzzの実装と正確には違うのですが、今回はより正確な命令実行数を取得するため、「検討」と書かれていた正確な命令追跡を行いました)。なぜ命令実行数にしているか、という点が気になった方がいれば、論文の5.6節を見ることをお勧めします。
さて、上記の通り、SLowFuzzでは命令実行数が必要となります。今回は、Intel Pinを使って命令実行数を取得し、その情報をAFLと共有させるようにしてみましょう。共有する方法ですが、共有メモリである trace_bits を4バイト拡張して、そこに命令実行数を格納するようにしました。共有メモリを拡張するには、afl-fuzzの setup_shm 関数にある shmget の第2引数を、 MAPSIZE から MAPSIZE + 4 にすればできます。拡張した4バイトには、基本ブロック単位で命令実行数を加算していくようにします。
最終的に出来上がったAFLとIntel Pinのコードは、それぞれ以下にあります。
プログラムを正常に実行できた場合、以下のような画面が出るはずです。このafl-pin-slowfuzzでは、実際のSlowFuzzとは異なりますが、AFL本来の機能に加えて、命令実行数の多い入力を生成しやすいように設計してあります。

おわりに
今書いた記事を見返してみて雰囲気しか伝わらなさそうな気がしてます
いかがだったでしょうか。おそらく、この記事を読んだ大半の方が、最初に「ファジング」という用語を聞いて、どのようなものか理解できなかったのではないかと思います。ファジングは海外では結構認知度があるように感じられるのですが、どうも日本ではあまり話題を聞かない気がします。
今回はIntel Pinを組み合わせましたが、他にもシンボリック実行ツールを組み合わせたものや、テイント解析を組み合わせたものなど、様々な種類が存在します。また発見したい入力についても、脆弱性の発生するもの、速度が遅くなるものなど、様々です。
そういえば、最近[1812.00140] Fuzzing: Art, Science, and Engineeringという、ファジングに関する調査論文が出たようです。(恥ずかしながら、まだ読めていません…)この論文のFig. 1を見ると、IEEE S&P 2018で発表されたCollAFLやAngoraなど、最新のものまで紹介されているようです。 ACM CCS 2018で発表されたHawkeyeはないので、そこまで最新のものはないのかもしれません。(近日、別のアドベントカレンダーで、いくつかのファジングの論文について話そうと思っていたのですが、どうしましょう…)
もっと日本でファジングに関する話が活発に聞けたらなぁと思う今日この頃です。というところで、技術的な内容が多くて理解できない部分があったかもしれませんが、本記事は以上となります。明日はmoppoi5168さんのBadUSB関係のお話です。お楽しみに!